disclaimer
This article reflects earlier work at Superlinear.
Our focus has since narrowed and deepened toward enterprise-wide orchestration to remove structural productivity bottlenecks across complex organizations. Today, we focus on long-term operational performance in mission-critical European industries.
To understand how we approach this now, visit our homepage.

Article
As excitement has grown around Machine Learning, more and more companies are attempting to leverage it. However, many projects are languishing and not returning the promised results. MLOps attempts to solve many of the issues plaguing these projects and finally allows ML to deliver the benefits it promises. We, at Superlinear, are in the unique position to have implemented ML projects successfully across many industries and use cases.
In the past, we’ve written about MLOps and its principles at a high level, for example, in our recent post on moving from DevOps to MLOPs. In this series of blog posts, we aim instead to give you an in-depth look at what some concrete implementations of MLOps look like in the form of various “MLOps Stacks”, each tailored to a specific use case.
In part 1 of our series, we discussed how to serve and scale multiple Computer Vision models for a mobile app. These articles aim to go into the technical details around each stack and are aimed at Machine Learning Engineers.
Live predictions of key business metrics
The MLOps stack discussed in this part 2 of our blog post series was designed for developing and serving models to predict key business metrics in near real-time. Models built with this stack integrate directly into a kafka-based data platform. These models can be used to power dashboards or fed as inputs into other systems. This stack is appropriate for companies with a mature streaming-based data platform. Examples could be logistics companies or manufacturing companies, but any company with a lot of live data looking to get insights from it could benefit from this stack.
Key challenges
Many fundamentals need to be covered by an MLOps stack, but the following are the ones that we found to be especially important in this use case.
Integrate into the existing data platform - For an organization that already has a mature data platform, it’s important that data science can be built on top of it. Both training and inference need to leverage this infrastructure.
Automation - Since data can change rapidly in a streaming-based environment, it’s vital to monitor your system and be able to react to them in an automated fashion.
Traceability - Since some model predictions can be critical to making highly influential decisions within a company, it’s vital that one be able to know exactly what those decisions are based on.
This stack was designed to be deployed on AWS and uses many AWS tools. Most of the AWS-specific services we use here could easily be replaced by services from any other cloud provider.
Architecture
An MLOps Stack should support the full life cycle of a machine learning model. To structure this, we’ve split the life cycle into four different steps:
Data Acquisition - The first step in developing any model involves acquiring data to train your model on. The primary driver of model performance is the quality of the data it is trained on, so getting this right is very important.
Model Training - Once you have data, the next step is to train your model on this data. Often you’re not sure which model to use, so being able to experiment rapidly requires this step to facilitate that. Further, since this is where your model is created, it’s important to ensure that everything you do here is reproducible.
Deployment and Packaging - Once you have a trained model, package it and deploy it to your serving infrastructure. How you package your model will determine how other services will interact with it. Being able to deploy new models quickly and in an automated way allows you to quickly update models in production and always provide the best models possible to your users.
Model Serving and Monitoring - Finally, once you have a deployable model artifact, you need to set up infrastructure to serve it to your users and to monitor it. Monitoring your model is important as it allows you to ensure that it is performing as expected.
Data acquisition
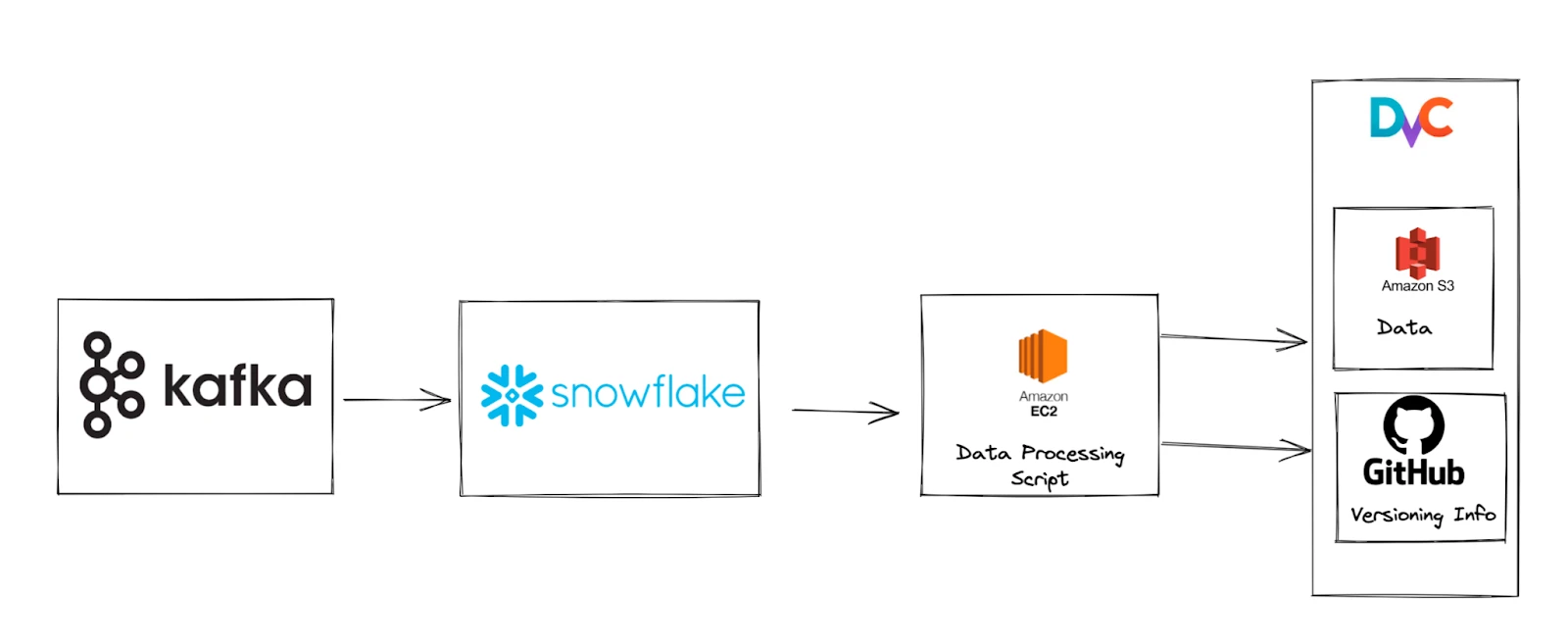
Data from Kafka is ingested into Snowflake. A data extraction script is run periodically to extract the latest data from snowflake and transform it into a form ready to be used to train the relevant model. This data is then tracked by dvc. Data is stored on S3, and versioning info is kept in Github along with the rest of our code.
Pros
Continually acquire new data to keep improving the model and avoid data drift.
Integrated directly into the organization's data infrastructure.
Data versioning with DVC.
Training
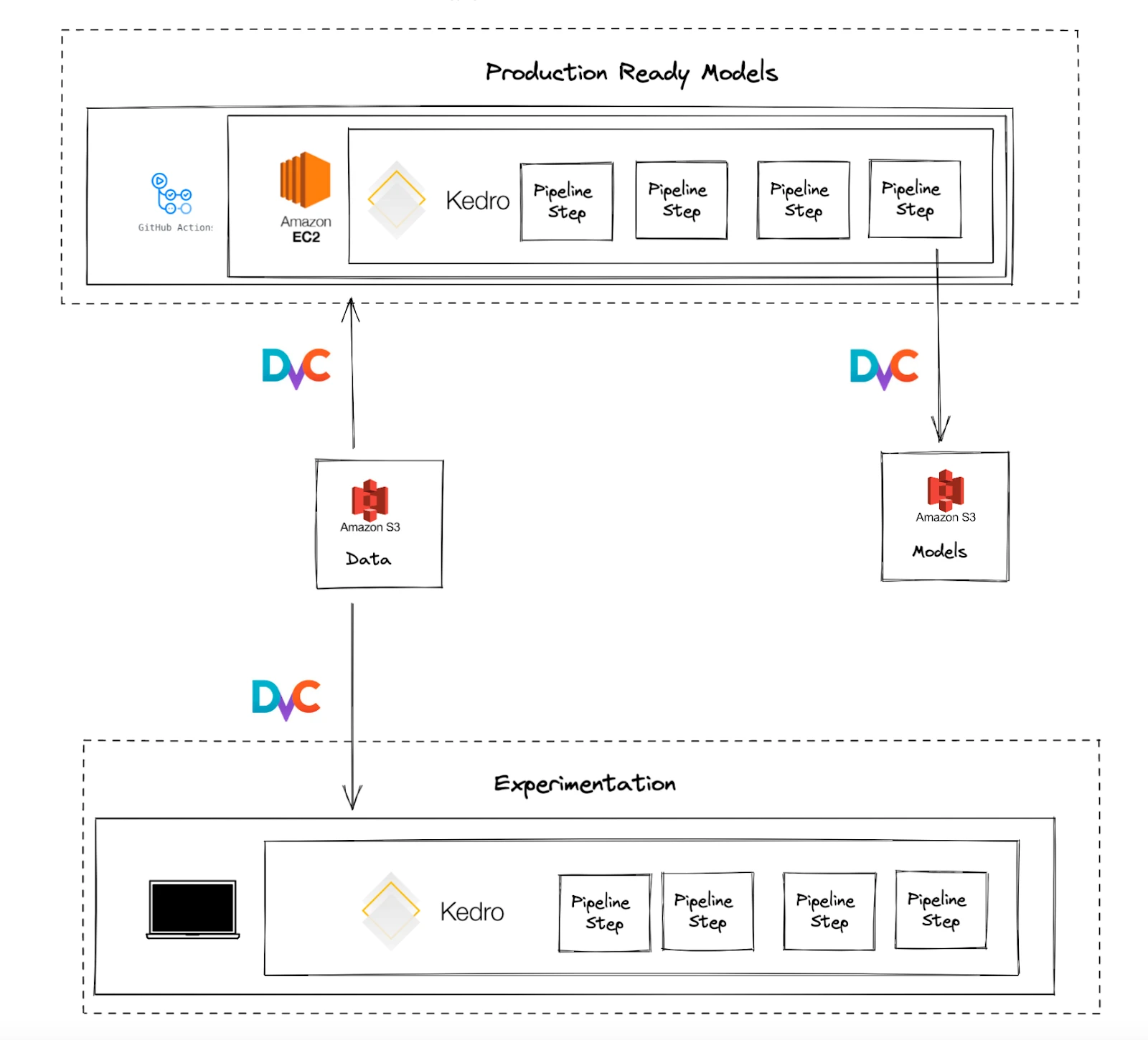
All model pipelines are created in Kedro. Previously generated versioned datasets are used as inputs to the pipeline. Some experimentation takes place locally, but production-ready models need to be trained via github actions pipelines run on our custom-managed github actions runners. This ensures full reproducibility since the code, data and environment are versioned. This also gives easy access to scalable computing. The resulting models are saved in S3 and tracked with dvc.
Pros
Data Science best practices with Kedro.
Run anywhere with Kedro pipelines.
Data and model versioning with DVC
A “deploy code” strategy to ensure model reproducibility.
Scalable compute managed via self-hosted github actions runners.
Keep data within your own ecosystem with self-hosted github action runners.
Deployment and packaging
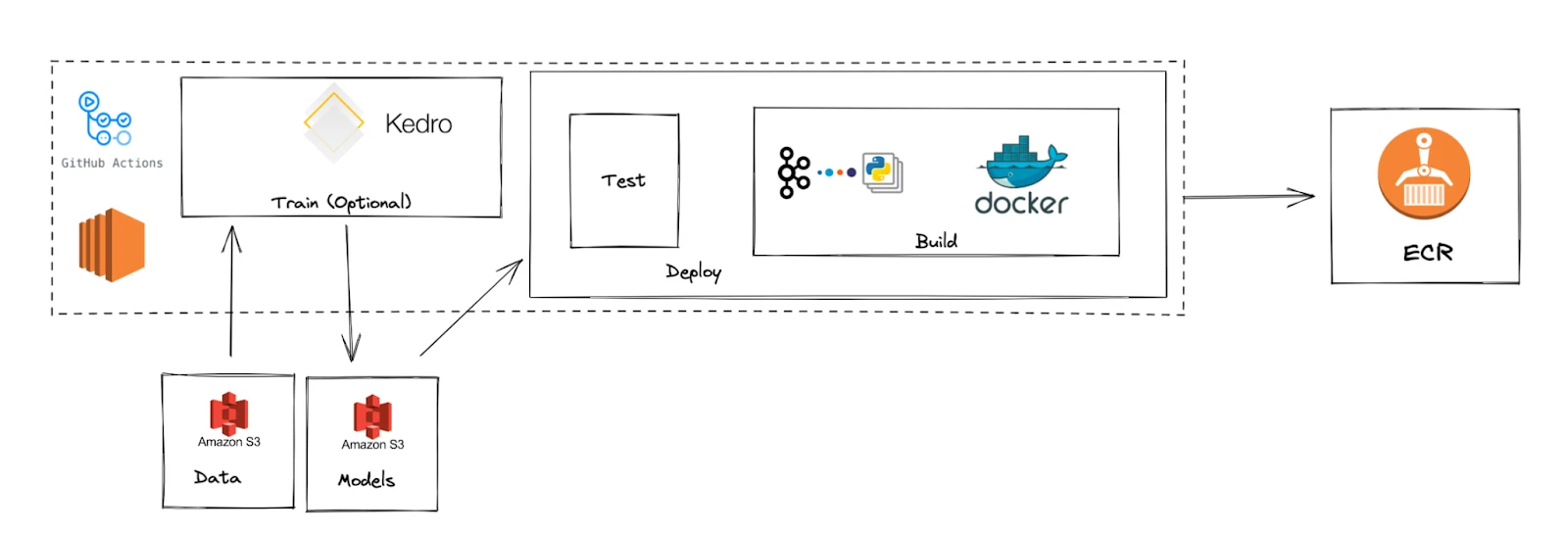
Trained models are tested to ensure that they continue to perform as expected. A python based Kafka interface is then set up so that models can use Kafka topics as inputs and write their outputs to other topics. This is all packaged as a docker image. The docker image is then uploaded to Elastic Container Registry, ready to be deployed.
Pros
Model testing ensures that the model performs as expected.
Easy cloud deployment with docker images.
Kafka Python client is easy for python based developers to use.
Integration into kafka allows the model to easily be integrated into a streaming-based system.
Serving and monitoring
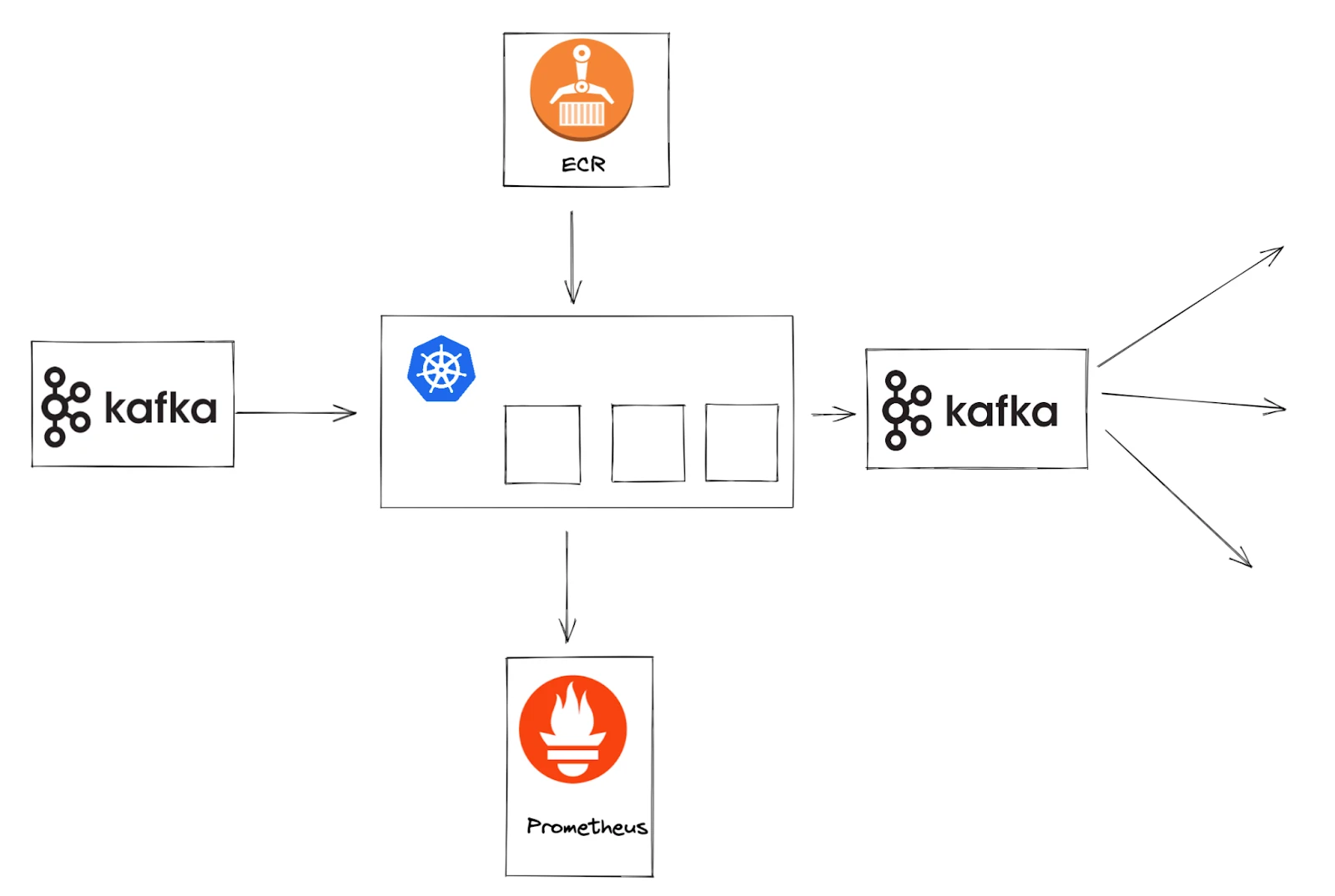
Kubernetes is used to manage a cluster of containers running the model with a Kafka interface. Containers containing the latest available model are automatically loaded from the ECR. While running logs are saved to Prometheus to provide insights into the running models.
Pros
Fully orchestrated deployment with Kubernetes
Logging with Prometheus
Easy integration with the business data platform via Kafka.
The next level
As with all projects, there are always new features to add. Here are the ones we’d look at next for this use case.
Automated retraining - Currently, no automated retraining is implemented. Since data in this context changes rapidly, automated retraining could be used to ensure the model stays as performant as possible.
Feature store - Currently, keeping features in line during training and inference is a delicate balance since feature engineering isn’t identical. Ideally, this should be done via a feature store such as Tecton or Feast.
author(s)

Jan Wuzyk
Solution Architect