disclaimer
This article reflects earlier work at Superlinear.
Our focus has since narrowed and deepened toward enterprise-wide orchestration to remove structural productivity bottlenecks across complex organizations. Today, we focus on long-term operational performance in mission-critical European industries.
To understand how we approach this now, visit our homepage.

Article
Imagine a system that makes developing and maintaining production Machine Learning seamless and efficient. A system that is a single technical solution to the challenging undertaking of machine learning. Often framed as the holy grail for successful Machine Learning, MLOps is your answer. This blog post will look at what makes MLOps such a popular framework and why you and your team should practice MLOps. We’ll also look at how to start with MLOps without introducing any new tools.
What is MLOps?
A quick Google search will tell you that MLOps (Machine Learning Operations) is no more than DevOps for ML systems - a single technical solution. However, the data science community disagrees strongly with this statement. It defines MLOps as a framework gathering best practices and guiding principles to streamline the continuous delivery of high-performing machine learning models in production.
“MLOps is a framework to help your company bring high-performing machine learning models to production continuously.”
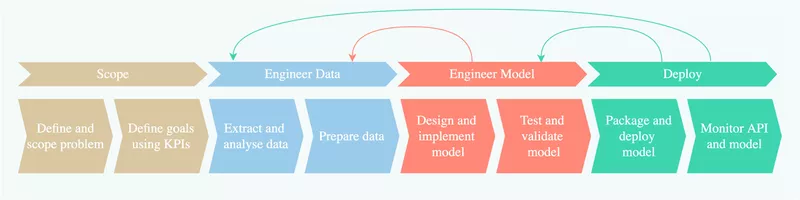
The ML Development Lifecycle (MLDLC)
To properly understand why MLOps is crucial for your ML projects, we have to understand the complexity of a typical Machine Learning Development Lifecycle. The MLDLC is an extension of the well-known software development lifecycle and consists of four stages:
Scope - Understand the problem and define business goals. You should formalize goal setting in ambitious yet achievable KPIs.
Engineer Data - Acquire data that will be used for training. This includes data extraction, analysis, validation, and preparation. Proper data validation by computing statistics is key to avoid sudden surprises.
Engineer Model - Design and implement your ML architecture. This includes unit testing and validation using a hold-out test set. Avoid staring blindly at average performance, and proactively measure performance on edge cases that are important to your business.
Deploy - Integrate the trained ML model into a business app. This includes model packaging, serving, and monitoring. Monitoring should take a pulse of both API performance and model performance.
Importantly, we must embrace that machine learning is more empirical and iterative than traditional software engineering. This is visualized by feedback loops that enable us to take a step back, improve, and retry. You should avoid spending too much time capturing data for your first iteration, so you start the iteration loop as quickly as possible. Getting fast to model validation and deployment will help you measure feasibility sooner and prioritize improvements for future iterations.
Guiding principles of MLOps
The MLOps framework sets forward four guiding principles for machine learning projects.
Machine Learning should be:
Collaborative: you must be able to collaborate asynchronously
Reproducible: you must be able to reproduce existing models
Continuous: you must be able to deploy and retrain effortlessly
Monitored: you must be able to track technical and predictive performance

Why should you practice MLOps?
Until recently, most companies were only using Machine Learning for small Proof of Concepts that seldom saw the light of day. Today, the scene is different, and AI is a fundamental part of real-world solutions critical to business. Managers and leaders realize that Machine Learning only brings value when used in production. This shift from POC to in-production ML introduces technical challenges that the traditional software development lifecycle cannot cope with.
“Machine learning only brings value when used in production, so getting them into production ASAP is key.”
Luckily, MLOps promises to solve these technical challenges. MLOps introduces a new engineering culture that accelerates the release of AI models and returns value.
Benefit 1: Proof of Concepts become valuable
Recently, putting machine learning models into production has been flagged as the most prevalent bottleneck. A study from VentureBeat reports that 9 out of 10 Machine Learning models never make it to production. As a result, data scientists rarely get the chance to produce something useful for the company. Meanwhile, the business loses crucial momentum.
Development bottlenecks arise because there is a disconnect between data science teams and operations teams. Data science teams tend to focus on the model while neglecting practicalities like model size and interface to bring their model to production. You can see it as a data science team throwing a Machine Learning package over the wall with a post-it attached that reads: “ready for production, please deploy ASAP”.

Source: Seven Signs You Might Be Creating ML Technical Debt
Benefit #2: Keep your team fresh
MLOps best practices frames ML projects as a pipeline and not just a model. As a mental model, pipelines help your team compartmentalize work effectively into work packages. This allows for the automation of manual work and the distribution of value-adding responsibilities across the team. Work packages enable parallel working, giving more head-space and instilling a “fail fast, learn faster” culture.
Pipeline-centricity also pushes your team to build modules that can be run multiple times. With this, ML projects become an iterative process instead of a one-shot attempt at a successful outcome. Turning ML projects into an iterative, experimental process helps your teams get into momentum and increases your chances of building a model that actually works in a production setting.
Benefit #3: Never lose track of your models
For decades, version control has been the modus operandi in traditional software engineering. In contrast, version control is often poorly executed in machine learning projects. For starters, data science teams often only push their final model iterations. Consequently, different models and iterations are lost, with recovery impossible. To make matters worse, training a model comprises more than just code. One training iteration alone is defined by code, data, and hyperparameters. Often, poor versioning results in lost value. As a result, Machine Learning engineers are left wondering how they achieved the performance they did and have no way to re-train a model that performs equally as well.

Besides reproducibility, proper versioning also helps companies comply with tightening regulatory requirements, e.g., GDPR in the EU or the Algorithmic Accountability Bill in New York City. Regulations require model predictions to be explainable. The first step in explaining why a model performs a certain prediction is knowing how the model was trained. Having data enables you to explain why a model might return biased results.
An operation MLOps infrastructure can reproduce models through proper data lineage and governance by version code, data, and hyperparameters. To do so, it helps engineers automatically track training iterations through metadata and code flags.
Benefit #4: No unexpected disasters
Many data scientists focus primarily on maxing out average performance on a hold-out test set. While this focus does simplify the evaluation process, high test set performance does not guarantee success in production. Firstly, the types of data that the model sees in production can be different from the training data. When this happens, there is data drift. Secondly, the relationship between the input data and the predicted labels can be different. This is known as concept drift. When drifting happens, sudden disasters can occur whereby the business service starts to perform poorly unexpectedly.
MLOps pipelines solve this unexpected disaster issue through two best practices: model performance monitoring and continuous retraining. Model performance monitoring observes potential negative effects of data drift and concept drift by measuring how well the model handles real-world data and how real-world data is different from training data. Continuous retraining, on the other hand, retrains and redeploys machine learning models. Retraining occurs on a new training set that contains data from production. In other words, retraining happens with a fresh batch of feedback from production. In most cases, retraining is triggered when data drift or concept drift is observed. However, retraining can also be triggered when a test reveals the trained model is too biased, or when your business users give negative feedback on the results of your model.

Benefit #5: Accelerate development across team boundaries
Fragmenting your large Jupyter notebooks and local data into manageable pipeline components helps your team get into the flow of designing generic solutions instead of one-stop solutions. Reusable components are key to any company, especially large corporations, as they enable teams to share solutions and know-how asynchronously. In turn, this will accelerate the pace at which your company can pump out new intelligent models.
For example, let’s say your team in the UK design a vision system to label images in English automatically. Since they designed a fine-grained pipeline for the system, differentiating components such as data-augmentation strategies, label-validation, and classification models are now each constructed in small reproducible components. When your team in China wants to solve a similar problem, they can easily re-use key components of this vision system to build their own image classification system.
Getting started
MLOps tools are everywhere. According to Forbes, the MLOps solutions market is about to reach $4 billion by 2025. With already more than 300 tools available, it is clear that MLOps is here to stay. Before you get excited and start perusing tools, it's essential to align on the why and how. Why do you want to implement MLOps? How will your team realize MLOps's guiding principles? Once you have the why and how, it will become easy to select tools and convince your team to use them.
Here are some practical ideas on applying the four principles systematically without introducing too many tools and technologies.
# Principle 1: MLOps should be collaborative:
Promote a train-on-commit policy to discourage people from running experiments locally. Implement a CI/CD strategy that trains and validates models automatically upon every commit. To quickly set up a train-on-commit infrastructure, I'd recommend you look at Sagemaker MLOps pipelines or Azure ML pipelines. It facilitates the orchestration and management of the complete ML pipeline, including training, evaluation, and deployment.
Apply software engineering best practices: create re-usable interfaces, use proper naming conventions, and divide your code into consumable functions. As far as interfaces go, I'd strongly recommend you look at sklearn pipelines and sklearn's base classes for estimators.
Document, document, document. Robust documentation is key to any project, and this also applies to your Machine Learning project. Start by documenting every step in your data pipeline and Machine Learning pipeline.
# Principle 2: ML should be reproducible:
Version your data pipeline and model pipeline experiments separately. Versioning pipelines should not cause too much overhead. A first version should memorialize the input data, code, and hyperparameters. To easily track versions, I recommend you have a look at a fantastic tool: DVC. DVC enables you to version your data and models using git-like commands compatible with any CI/CD pipeline.
Additionally, I recommend you write down the hypothesis you are evaluating with each run. Tracking hypotheses will give your peers insights into your thought process and allow you to backtrace failed attempts.
# Principle 3: ML should be continuous:
Separate the pipelines for processing data and training your Machine Learning model. Try to decompose each pipeline into small, manageable components that can be tested and developed separately.
Trigger periodic retraining and redeployment of your Machine Learning model using bash scripts or workflow management platforms such as Airflow, Azure Data Factory, or AWS Glue
# Principle 4: ML should be tested and monitored
Monitor your data and label distributions to detect drifts or changes that can affect your performance. Data drift and concept drift occur when you least expect them. Make sure you have an alarm in place that warns you when the deployment context of your model is different from its training context. Better yet, use this alarm to trigger automatic retraining and redeployment using new training data. That way, you won't have to worry about any data or concept drift in the future.
Monitor the input data and the responses of your model in production and trigger an alarm when inconsistencies occur. Examples of inconsistencies include an increase in the number of empty responses or a decrease in the diversity of output labels.
Apply deployment strategies that enable you to compare multiple iterations of your algorithm in real-world settings, such as canary tests or A/B tests. It can happen that your hold-out test set is not representative of your model's real-world performance. Using thought-through deployment strategies will help you understand how well your model is doing compared to older versions. Numbers from A/B tests are always more impactful as they give you numbers directly to build a business case.
Conclusion
MLOps became a cornerstone of machine learning projects. Pragmatically applying MLOps’s guiding principles enables you to draw value from AI faster by continuously building high-performing machine learning models. Now it’s up to you to take action! Apply MLOps’ guiding principles in your next machine learning project.
author(s)
Enias Cailliau