disclaimer
This article reflects earlier work at Superlinear.
Our focus has since narrowed and deepened toward enterprise-wide orchestration to remove structural productivity bottlenecks across complex organizations. Today, we focus on long-term operational performance in mission-critical European industries.
To understand how we approach this now, visit our homepage.

Article
As excitement has grown around Machine Learning, more and more companies are attempting to leverage ML. However, many projects are languishing and not returning the promised results. MLOps attempts to solve many of the issues plaguing these projects and finally allows ML to deliver the benefits it promises. We at Superlinear are in the unique position to have implemented ML projects successfully across many industries and use cases. In the past, we’ve written about MLOps and its principles at a high level, for example, our recent post on moving from DevOps to MLOps. In this series of blog posts, we aim instead to give you an in-depth look at what some concrete implementations of MLOps look like in the form of various “MLOps Stacks”, each tailored to a specific use case. These articles aim to go into the technical details around each stack and are aimed at Machine Learning Engineers.
Computer vision for a mobile app
The MLOps stack discussed in this part I of our blog post series was designed for developing and serving multiple Computer Vision models, providing extra functionality to a client's mobile application. The client used their app to enter data, and with computer vision, we managed to automate many of the data entry tasks, improving both the speed and accuracy of the process. An example of a similar use case would be supporting workers using an app during inspections in a factory, or postal workers logging delivered packages.
Key challenges
Many fundamentals need to be covered by an MLOps stack, but the following are the ones that we found to be especially important in this use case.
Continuous Data Collection - Model performance is largely reliant on the quality of the data you have. In this case, especially since the environment in which the models are being used is constantly evolving. Having a robust pipeline to continuously collect more high-quality data is critical to ensuring our models get the best performance possible. Since we were working with the client on features for an existing app, we managed to quickly set up a data acquisition pipeline using real data from the field.
Automation - We worked with a small team of engineers, so using a MLOps platform (AzureML) and a lot of automation was needed to continuously improve multiple models simultaneously.
Optimized Serving - Since we are trying to give end users feedback in near real-time, it's critical that we can get results from our models fast. To facilitate this, we used tools specialized for serving machine learning models, like Nvidia Triton and TensorRT.
This stack was designed for a client with many infrastructures deployed in Azure, so it was only natural that we build on this and use many Azure tools. Most of the Azure-specific services we use here could easily be replaced by services from any other cloud provider.
Architecture
An MLOps Stack should support the full life cycle of a machine learning model. To structure this, we’ve split the life cycle into four different steps:
Data Acquisition - The first step in developing any model involves acquiring data to train your model on. The primary driver of model performance is the quality of the data it is trained on, so getting this right is very important.
Model Training - Once you have data, the next step is to train your model on this data. Often you’re not sure which model to use, so being able to experiment rapidly requires this step to facilitate that. Further, since this is where your model is created, it’s important to ensure that everything you do here is reproducible.
Deployment and Packaging - Once you have a trained model, package it and deploy it to your serving infrastructure. How you package your model will determine how other services will interact with it. Being able to deploy new models quickly and in an automated way allows you to quickly update models in production and always provide the best models possible to your users.
Model Serving and Monitoring - Finally, once you have a deployable model artifact, you need to set up infrastructure to serve it to your users and to monitor it. Monitoring your model is important as it allows you to ensure that it is performing as expected.
Data acquisition
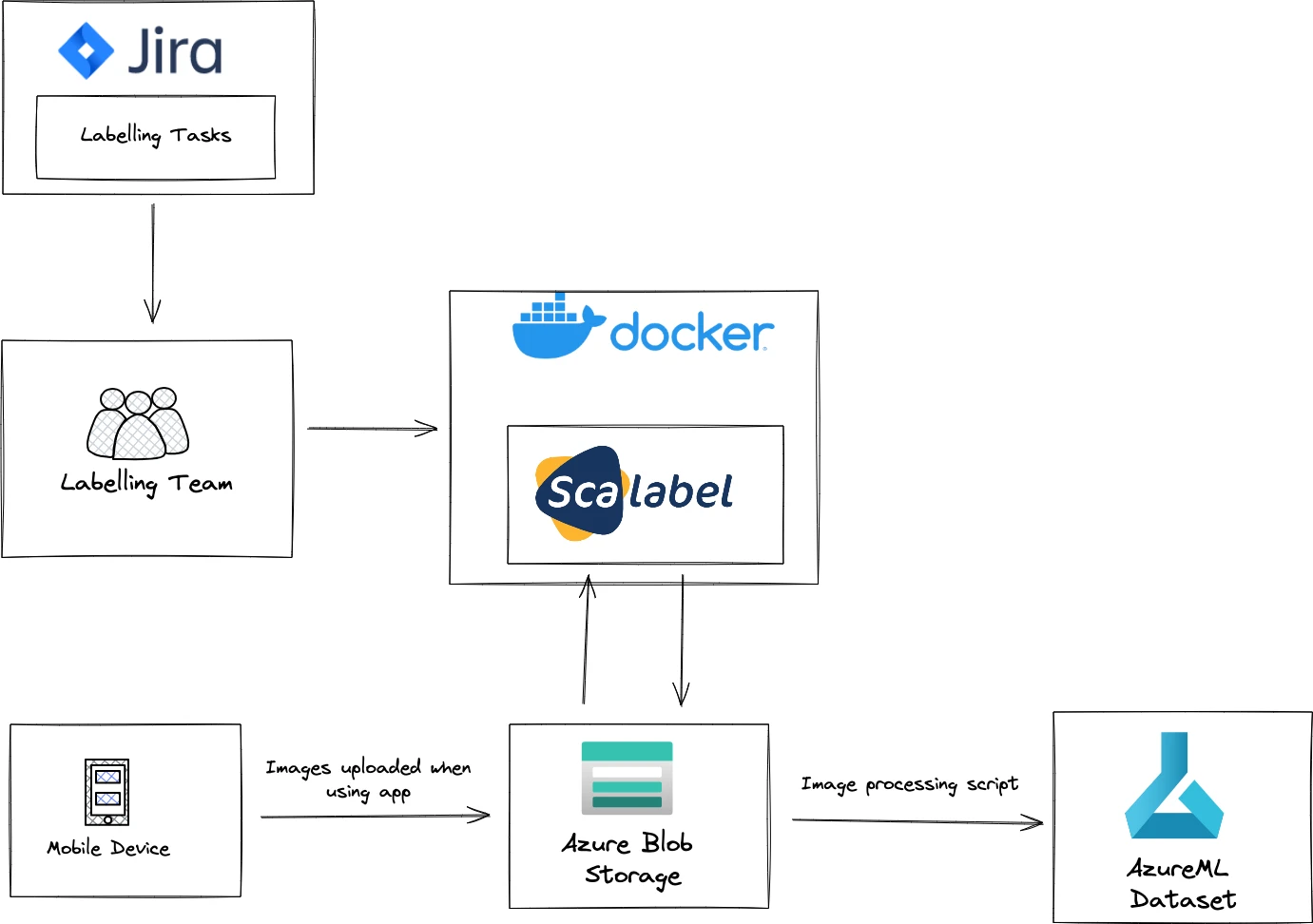
Images are collected when users use the app and are saved to Azure Blob Storage. We regularly generate JIRA tasks from these, which our labeling team then works through. This allows us to easily track their progress. We deployed docker containers running the labeling tool Scalabel to provide an easy-to-use labeling environment to labellers. Once images are labeled they are stored back in Azure Blob Storage with their labels. Finally, a job runs periodically to apply some final processing to the labeled images and create a new versioned data set in AzureML, ready for training a new model.
Pros:
Continually acquire new data to keep improving the model and avoid data drift.
Easily track labeling tasks with JIRA.
Easy to use labeling environment with Scalabel and Docker.
Cheap, versatile storage with Azure Blob Storage.
Versioned datasets with AzureML so we always know what data a model was trained on.
Training
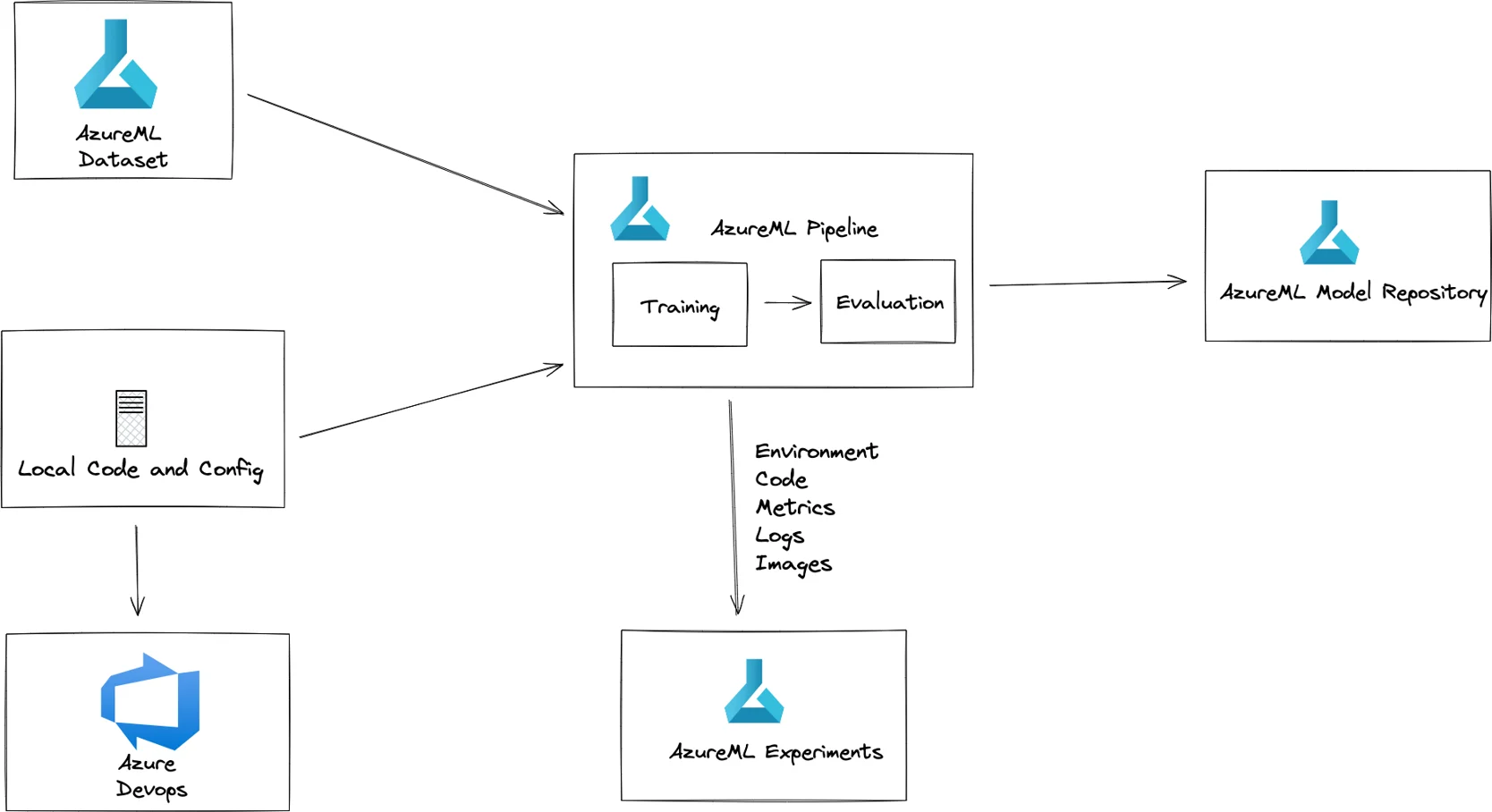
Training is done by submitting the training code and a versioned data set as an AzureML training job. All inputs are saved as artifacts in AzureML, ensuring reproducibility. This job is then run on a GPU instance to allow it to train in a reasonable amount of time. Metrics and associated visualizations are saved to AzureML during training, allowing us to easily visualize the model's training. Finally, the model is run through a custom evaluation script and saved to the Azure Model Repository, ready for deployment. Using Azure ML here allows us easy access to scalable compute resources, experiment tracking, and reproducibility, all with little extra effort.
Pros:
Easy access to powerful GPUs with Azure ML.
Follow the training and compare different runs with AzureML experiment tracking.
Full reproducibility is ensured since AzureML automatically saves the code, data and environment.
Easily track all model versions with the AzureML model repository.
An accurate view of the potential performance in production given by custom evaluation script.
Deployment and packaging

The model evaluation results are used to decide whether a new model should be deployed. If the model performance exceeds that of previous models, a pipeline is triggered. First, the model is optimized for serving by converting it first to the ONNX format and then into TensorRT format. The optimized model is then saved to a blob store functioning as the model repository for our QA deployment of NVIDIA Triton. Once thoroughly tested, the model is passed to our production deployment of NVIDIA Triton.
Pros:
Fast model inference with ONNX + TensorRT optimisation.
Simple packaging and deployment with NVIDIA Triton.
Through model testing before final release with parallel Dev and Prod deployments.
Serving and monitoring
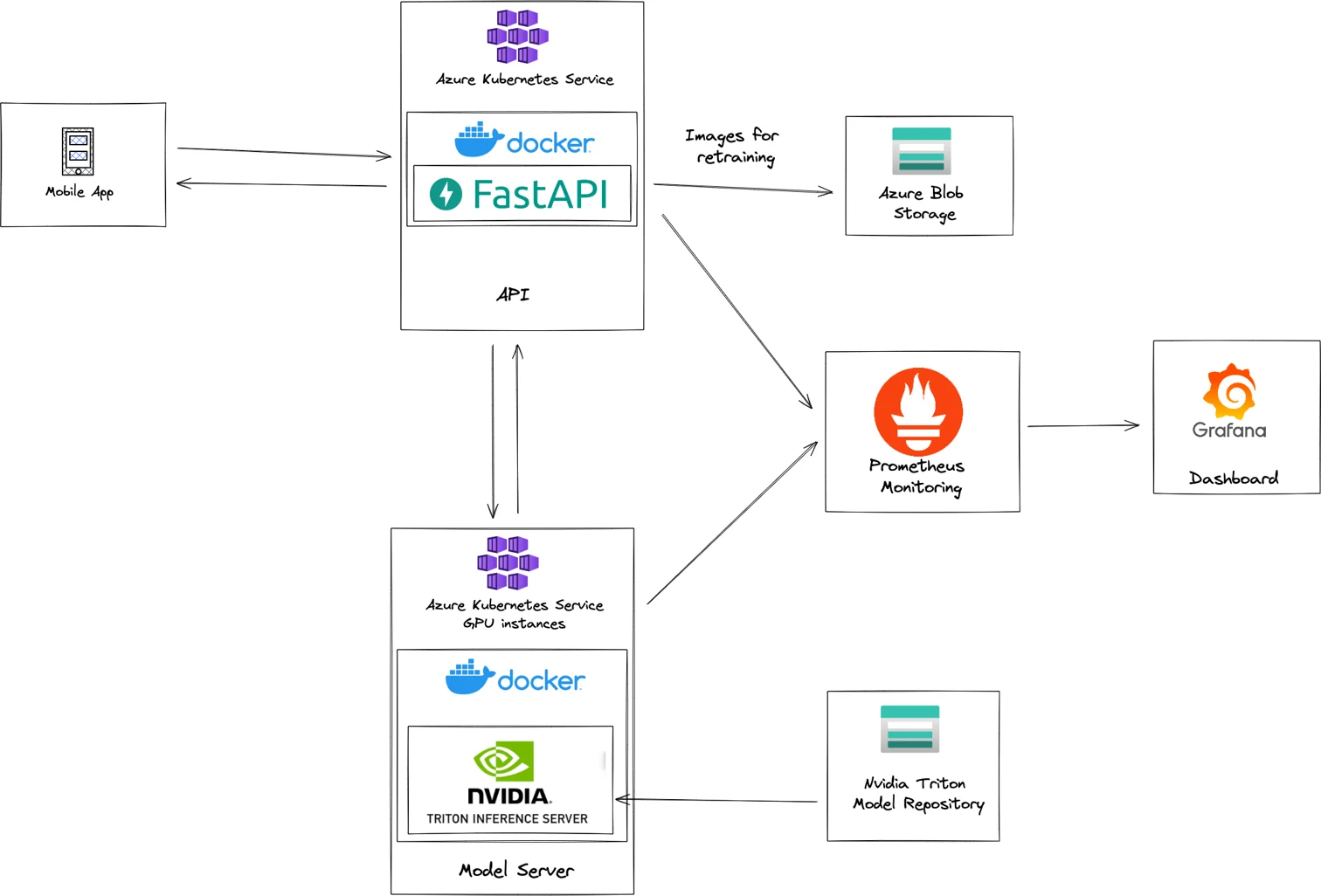
The model is served on an Azure Kubernetes Service GPU cluster running Nvidia Triton. Kubernetes allows us not to worry about manually handling the deployment, scaling or management of our containers, significantly reducing the work needed to maintain this deployment, and Triton gives us the best possible utilization of our expensive GPU instances. Calls are first processed by a dockerized FastAPI API which performs some initial processing and determines what requests need to be sent to the model server. These results are collected, and the full result is then sent back to the mobile application. Meanwhile, the model inputs are saved to blob storage to be retrieved later for retraining. This setup allows us to provide a much more customized API to the mobile application and handles many extra tasks without wasting time on the expensive model server. Metrics are captured in Prometheus and displayed in a Grafana dashboard to allow stakeholders to easily see how the models perform.
Pros:
Automated deployment, scaling, and container management with Azure Kubernetes Service.
Additional API handles business logic.
Simple API development with FastAPI and Docker.
Efficient GPU utilization with NVIDIA Triton.
Continuous data collection.
Easily share model performance with stakeholders via grafana.
The next level
As with all projects, there are always new features to add. Here are the ones we’d look at next for this use case.
Multi-GPU training - Training currently takes place on single GPU instances. Training time is becoming a barrier as our datasets grow, and we will need to extend our setup to run on multi-GPU machines or even clusters.
AI-assisted labeling - Currently labeling our images is quite a laborious task, but since we already have good models trained, we can leverage these to speed up and increase the quality of labeling.
author(s)

Jan Wuzyk
Solution Architect