In this article, you’ll learn how to think about your Machine Learning systems from a data-centric perspective by emphasizing the role of data in the process of creating a Machine Learning system.
Why data-centric?
The key to the run-away success of Machine Learning has been the explosion of available data paired with computing and models to leverage this data. Most content about Machine Learning focuses largely on the model aspect of this. This is true all the way from online blogs to published research. This is natural in academia as research in Machine Learning attempts to emulate the sciences by relying on repeatable experiments with measurable results.
Unfortunately, this is far from the whole picture when dealing with real Machine Learning projects. The true challenge and often the downfall of many Machine Learning projects occurs on the data end instead. In fact, in many cases support for the model-focused side of ML has already been worked out so well that easy-to-use, open-source implementations exist for many state-of-the-art models. This makes implementing powerful models easy but also means that if this doesn’t give sufficient performance, it is very hard to do better simply by finding a better model. Instead, focusing on a data-centric approach can give you better results.
A data-centric approach emphasizes the role of good data as the cause of good model performance as opposed to the specifics of the model. When trying to improve a model in this framework one instead asks: how can I collect and process my data to get the best performance?
To approach this problem we develop a heuristic about how ML models function. We can assume all models work as follows: given a new data point, the model checks which examples in its training set are similar to the new point and aggregates those to make a prediction. This isn’t quite the whole story and there is a lot of subtlety in the word “similar” which we will return to but for now, this gives us an easy way to think about Machine Learning without caring about the mathematical details of how any model works. Thinking of all models in this way has some consequences which we will now explore.
Collecting the right data
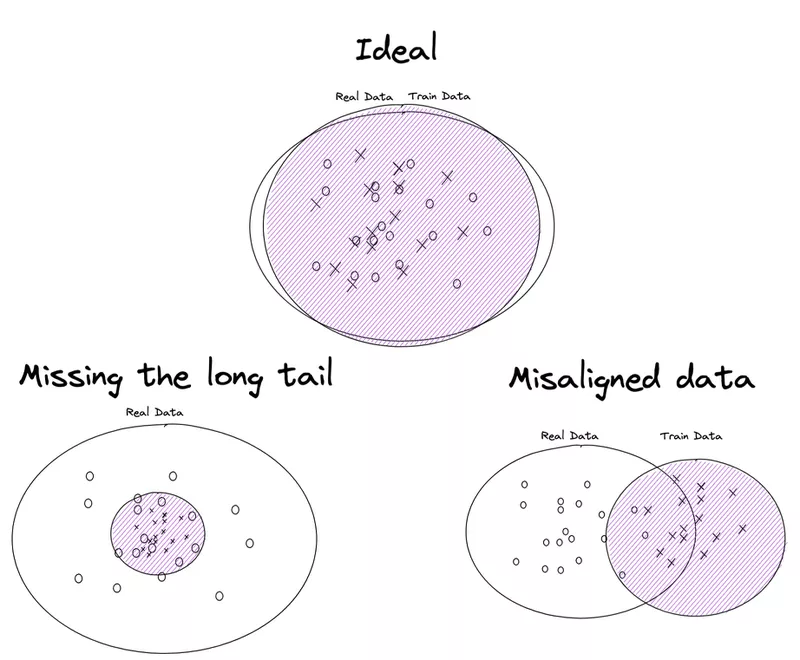
While more data is generally a good thing, which data you collect can have a large impact on how your model performs. In general, models perform well on samples that are similar to a lot of their training set and poorly on samples that aren’t similar to their training set. Two particular ways this fails are when you have misaligned data or when you miss the so-called “long tail”.
Misaligned Data
Misaligned data (also known as covariate shift) occurs when you train a model on data that is different enough from the real data it is intended to work on that it fails to generalize to the real use case. While this might seem obvious, it can manifest in surprisingly subtle ways or is often ignored when collecting real representative data is deemed too challenging. This issue can be particularly insidious as your test set, which you use to evaluate your progress, will likely also reflect your training data so you can easily fool yourself into thinking you’re doing well when you’re not.
One somewhat subtle way this occurs is in stock market prediction. The dynamics of the stock market change a lot with time so people who train models on historical data often find their models suddenly underperforming once exposed to real life. Ironically one of the reasons for this is people using new models. Once new models are introduced to exploit some misvaluation in the market, the market adapts to this and models exploiting this, which might work well on historical data, no longer work. The phenomenon where the real-world environment your model will have to deal with changes over time is called data drift. This doesn’t only apply to directly time-based data, for example, a food identification app could struggle to work when new food trends appear.
When you do have flexibility with the data collection process, you can make significant gains by taking care of how you collect your data. Generally, high-quality data which really reflects your use case is much more important than simply getting as much as possible from a more convenient source. The ideal would be to use exactly the same process to generate data as will be used in the final model. For example, if you’re developing an app to identify products in a supermarket, while it might be easier having photos taken in some warehouse, it would be much better to have them taken in actual supermarkets and preferably in a variety of locations as well. This will give you a much better reflection of the real use case leading to much better results in the end and will give you a much better view of how your model will perform in the real world.
Unfortunately, this problem is often unavoidable. Only in an ideal world will you always be able to access data identical to your real-world use case. In situations like these good performance tracking practices become key. It’s vital that you design systems that keep track of how well your model is working in the real world, not just on your internal metrics which could be giving overly optimistic results.
Missing the Long Tail
Even if all your training data does reflect the real data, some of the real data might not be reflected in your training set. In life, all events don’t happen equally often. Some are rare and some are common, so when you collect data you’re naturally biased to collect a lot of data for common situations and very little for rare ones. These rare events are often called the long tail. This directly leads to poor performance in those rare cases. In fact, once sufficient data has been collected for common cases, more data in these cases no longer leads to better performance. Unfortunately in some use cases, it’s exactly these rare occurrences that have the largest impact. For example, another 10000 hours of video from cars driving on highways in good conditions is unlikely to make Tesla’s self-driving any better as it already performs well there but 1 minutes’ worth of clips directly before crashes might.
To deal with these problems the best approach is often good old-fashioned common sense and understanding the domain you’re working in. Time spent exploring your data and learning what biases lie inside it is unlikely to be wasted. Once a basic dataset is established, it’s vital to focus on these rare edge cases to keep your model improving and improve robustness. Simply looking at your model’s predictions can often be a good guide as to what data is lacking as well.
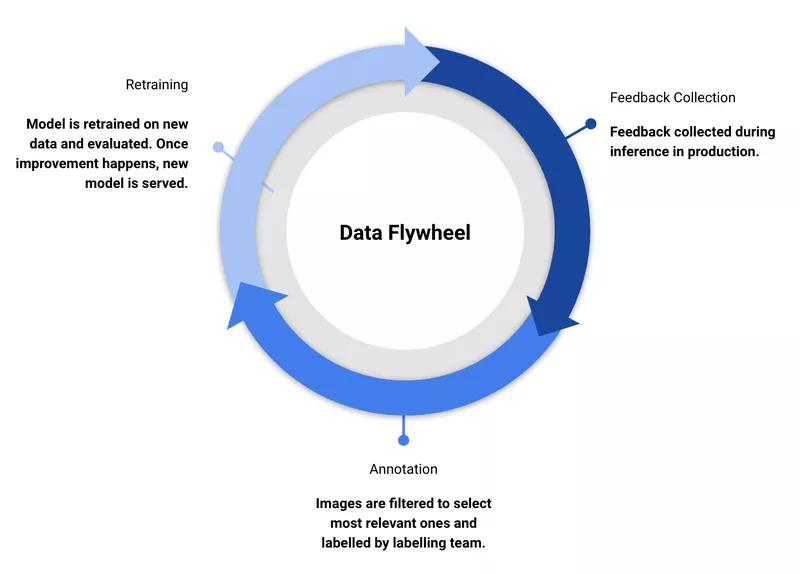
A particularly effective way to improve a model if it’s already being used in the real world is a data flywheel. This is a process where you continuously collect data from your production environment, assigning exactly those which model failed on to be relabelled and then retraining a model which will no longer have those weaknesses.
Model scope
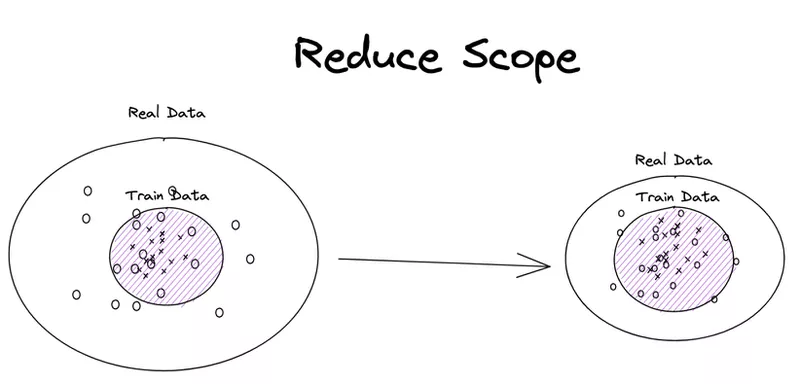
Finally, another consideration is the scope of your model. If you have limited data/ability to collect data, it might be worth considering limiting the set of real-life situations you expect your model to perform in. It’s easier to train a model if the model has a simpler task to perform. In many business contexts, a model that performs reliably under constrained conditions is better than one which performs erratically. For example, consider an image processing application where you identify food from photos of people's dinner plates. If your business case allows, you could reduce the amount of required data significantly by requiring that users take photos from a fixed angle, e.g. directly above. This likely won’t make the user experience much worse but will provide a performance faster with less data.
Ensuring high data quality
So far, I’ve been talking as if data is something that you can just go out and grab and what you get will always be exactly what you need. Unfortunately, this is generally not the case, real data is messy, imprecise, and full of noise and generally requires labeling which if done poorly can introduce even more chaos. If your data fails to paint a clear picture for your model it won’t be able to make meaningful predictions. So great care must be taken with the whole process to ensure the results you want. While massive amounts of data can overcome some of the issues with poor quality data (if you have enough data points voting on each inference it should be correct even if some are wrong), this is generally not an effective approach.
The process begins with how data is collected. It will be much easier for your model to find patterns when it only looks at relevant data. Including a lot of irrelevant data or data which isn’t consistently formatted hides any patterns your model needs to find. A few more hours making sure you’re only scraping data from the correct parts of a website or making sure it’s all in the format you expect will pay off further down the road.
If you need to label your data, it’s important to be consistent and correct. Confusing labels will hamper your model’s performance. While this might sound obvious in some cases it can be quite a delicate question. Different labelers might have different opinions on the correct labels for data. For example, which are the correct bounding boxes for the iguanas in the image below? The best way to prevent these issues is to make sure you have clear labeling guidelines and have multiple annotators check each other's work and only use data that they agree on.
That said it’s always a good idea to go through your data to look for labeling errors. One tool which can be useful for this is the field of confidence learning.

Source: MLOps: From Model-centric to Data-centric AI
Get the most of the data you have
Augmentation
While collecting more data to improve a model or modifying our labels would be ideal, often we’re stuck with what we have. Even here some data-centric ideas can be useful. Often we can modify our data in some way that provides a new data point but we know still preserves everything important for our model. If we rotate an image of a car, it remains a car. Often if we replace words with synonyms, a sentence's meaning will remain the same. These transformations which change our data but preserve the structure we care about can allow us to generate a near-infinite amount of examples in some cases. Further, we can think of these as ways to teach the model about certain aspects of the problem that we know, for example, that rotations don’t change what objects are in an image. This allows us to inject our understanding of the world into the model.
Feature extraction
We can go a step further and extract quantities from our data which we think will be relevant to the model, reducing the amount the model has to learn. If you want to predict sales of toys, while given enough data a model might work out that there is a spike around the 25th of December each year, simply adding an extra feature indicating whether a date falls in the Christmas season will give you better results with less data
Transfer learning
While it might seem counter to everything I’ve said so far, often there are ways to leverage noisy data, unlabeled data, or data intended for other tasks to improve your model but generally, you will still need a core dataset of high-quality data. One way to think of this is that many models include an element that learns what it means for data points to be “similar”. While filling in missing words in sentences might not be at all the same as predicting whether someone likes gardening from their bio, the notion of what it means for a text to be similar which will be learned by a model performing the first task is still quite useful for the second task. Thus if we begin with a model which performs the first task on a massive corpus of data, let it get quite a good idea of what it means for sentences to be similar, then switch to the second task, for which we have much less data, we can still use the notion of similarity learned on the first task to perform much better on the second.
Conclusion
Data, often more so than models, is what differentiates successful ML projects from duds that never make it past a PoC. Taking care to make sure you are collecting the right data and handling it well should be a priority. The key takeaways are:
Data must align with your real use case
Data must cover all cases
Restricting your problem scope can give good reliable results with less data
Data must be consistently labeled
Data augmentation, feature engineering, and transfer learning are approaches to try if you have limited data.
The field of MLOps provides a lot of tools to streamline the process of collecting good data. For more on MLOps check out this great blog post by Enias, from Superlinear. For more on Data-Driven ML from one of the greats of ML, check out this talk.