disclaimer
This article reflects earlier work at Superlinear.
Our focus has since narrowed and deepened toward enterprise-wide orchestration to remove structural productivity bottlenecks across complex organizations. Today, we focus on long-term operational performance in mission-critical European industries.
To understand how we approach this now, visit our homepage.

Article
Since the release of GPT-2 in 2019, large language models (LLMs) have evolved dramatically, from basic paragraph summarization to surpassing human performance on expert-level benchmarks. This progress can be attributed mostly to three factors:
Increased compute: More powerful computational resources.
Algorithmic efficiency: Improved algorithms that make better use of existing compute resources.
Unhobbling techniques: Strategies that remove inherent limitations of LLMs.
Yet even the most powerful LLMs remain hobbled in different ways: they're confined to the knowledge from their training data, have limited reasoning time, and are typically unable to interact with external environments or tools. Imagine being asked to answer complex questions instantly without any external references, you'd likely struggle too.
To address these limitations, researchers, and practitioners apply various “unhobbling” techniques, including external tool integration, increased inference times, and notably, effective prompt engineering techniques. Among these, structured prompts, leveraging methods such as Chain of Thought (CoT), XML formatting, and few-shot prompting, have emerged as powerful techniques.
What is prompt engineering?
Prompt engineering is the practice of designing precise, structured and effective instructions that guide large language models (LLMs) like GPT toward producing more accurate, relevant and context-aware outputs.
Due to the inherently non-deterministic nature of AI-generated content, meaning the same prompt can produce slightly different answers, creating effective prompts that consistently yield the desired results blends both art and science. Fortunately, several proven prompt engineering techniques and best practices can help you achieve dependable and high-quality outcomes.
Certain LLM prompting strategies, such as utilizing message roles, are broadly effective across various models. However, different model architectures, for instance, reasoning-focused models versus GPT-based models, may require distinct prompting strategies for optimal performance. Additionally, variations among different versions or snapshots within the same model family can also influence the effectiveness of particular prompts.
Best practices to improve LLM performance
1. Get the basic right
When crafting prompts for large language models (LLMs), it's essential to follow a few core AI prompting strategies to ensure high-quality responses.
Be explicit with your instructions: clear, specific directives help the model understand exactly what you want, especially if you're aiming for nuanced or advanced behaviors.
Add relevant context or motivation behind your request: explaining *why* a certain output matters can help the model better align its response with your goals.
Pay close attention to the examples and details you provide: LLMs learn from the examples you give, so they should reinforce the behaviors you want and avoid introducing unintended ones.
2. Structure prompts with XML
When dealing with complex prompts containing multiple components, such as context, instructions, and examples, incorporating XML tags can improve the performance of the model. Using XML tags allows the model to better understand distinct parts of your request.
By clearly delineating different sections of your prompt with XML tags, you reduce the likelihood of model misinterpretation, resulting in more precise and relevant responses.
For the best results, choose XML tag names that are consistent and descriptive, such as <instructions>, <context>, or <examples>. Additionally, nesting XML tags hierarchically helps represent structured or complex information clearer. There’s no such thing as the canonical, best tag so feel free to experiment.
3. Use few-shot prompting
Few-shot prompting means incorporating specific input-output examples directly into your prompts. This technique helps guide the model to recognize implicit patterns. This approach enhances quality and consistency without the need for extensive fine-tuning.
To maximize the effectiveness of few-shot prompting, it's essential to provide diverse examples that cover various scenarios, including critical edge cases. Frameworks like DSPy further expand this concept by iteratively selecting and optimizing the most impactful combinations of examples. DSPy can also generate synthetic data, kickstarting the optimization process.
4. Position critical information first
Positioning critical information effectively in your prompt impacts model performance, particularly for tasks involving long contexts. Place lengthy documents or detailed data at the start of the prompt to ensure that essential context is immediately accessible. You can even reiterate critical instructions or questions again at the end of your prompt to improve model performance.
5. Apply Chain of Thought (CoT) reasoning
Improving prompt performance can also be achieved through the “Chain of Thought” (CoT) prompting method, which encourages the model to approach complex tasks step-by-step.
CoT can be implemented with simple guiding phrases such as “Think step-by-step,” explicit reasoning instructions, or structured prompts using XML tags (e.g., <thinking> and <answer>) to separate the reasoning process from the final response.
For example:
Think before you write the email in <thinking> tags. First, think through what messaging might appeal to this donor given their donation history and which campaigns they’ve supported in the past. Then, think through what aspects of the Care for Kids program would appeal to them, given their history. Finally, write the personalized donor email in <email> tags, using your analysis.
6. Chaining prompts for complex tasks
For intricate tasks that require multiple detailed steps, break down the task into manageable subtasks. This technique allows the model to focus its attention clearly on each subtask, improving quality. Prompt chaining also enables isolated optimization of any problematic steps.
7. Reasoning models
When working with reasoning models, which typically excel when given high-level goals rather than precise instructions, it's more effective to provide broad objectives. This allows the model to independently determine intermediate steps that can lead to better outcomes compared to overly detailed instructions.
LLM cost optimization and LLM latency optimization
Beyond improving quality, prompt engineering can help you cut costs and reduce response times.
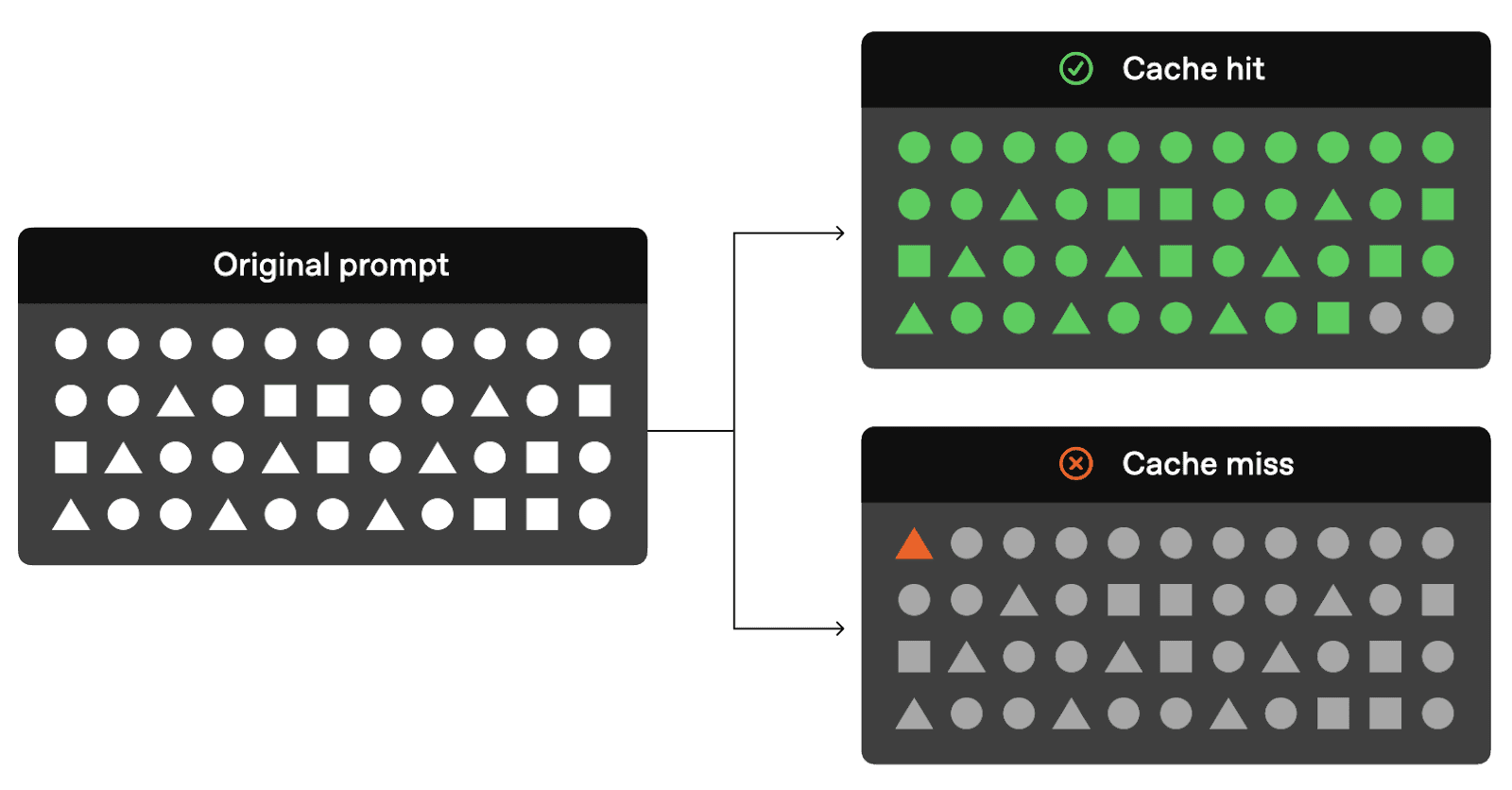
Prompt caching
Model prompts frequently contain repetitive elements like system prompts or standard instructions. Prompt caching routes API requests to servers that have recently processed identical prompts, significantly decreasing latency and costs.
For effective caching, ensure that static content, such as general instructions or standard examples, appears at the beginning of the prompt. Variable content, like user-specific data, should be placed toward the end. Most providers automatically provide this feature.
Note that this conflicts with our tip of placing important info at the beginning of your prompt. This means that you’ll have to prioritize cost and latency VS quality.
Source: Open AI platform
Prompt caching is particularly effective when combined with systems that serve repeated queries from a knowledge base, such as lightweight RAG setups like RAGLite, which benefit from efficient prompt reuse across similar retrieval outputs.
Predicted outputs
Some providers, like OpenAI, provide a feature called “predicted outputs” which reduces latency for responses when many tokens are known in advance. This approach is highly effective when regenerating code files for instance where you’re only making small adjustments.
Conclusion
Since GPT-2, LLMs have come a long way, but unlocking their full potential still depends heavily on how you prompt them. It’s not just about scaling compute or improving infrastructure.
Think structured formats like XML, well-crafted few-shot examples, Chain of Thought reasoning, and prompt chaining. These are ways to unhobble your model, helping it reason better, stay on track, and deliver more accurate, context-aware outputs.
Of course, every project has trade-offs. You’ll need to balance quality, latency, and cost. But if you’re thoughtful with your prompt design and caching strategy, you can get a lot more from your model without throwing more compute at the problem. As LLMs keep evolving, how you prompt them will matter just as much as what they’re built on.
FAQs about prompt engineering
1. Which technique is commonly used in prompt engineering to improve model performance?
Few-shot prompting is a commonly used technique in prompt engineering. It involves incorporating specific input-output examples directly into prompts to help guide the AI model in recognizing implicit patterns. This method enhances quality and consistency without extensive fine-tuning.
2. How to prompt AI more effectively?
To prompt AI effectively, follow best practices such as:
Clearly defining explicit instructions to guide the model's behavior.
Providing relevant context and motivations to align the model's response with your objectives.
Structuring prompts using XML tags to delineate instructions, context, and examples.
Employing methods like few-shot prompting and Chain of Thought (CoT) to help the model reason step-by-step and produce precise outputs.
Positioning critical information early in the prompt to improve context recognition.
3. How can prompts be used to optimize AI interactions?
Prompts optimize AI interactions by clearly structuring instructions, context, and examples, which reduces ambiguity and improves the relevance of the AI’s response. Techniques like XML structuring, few-shot prompting, and Chain of Thought (CoT) enable the AI to better understand and perform complex tasks. Prompt chaining further improves interactions by breaking down tasks into manageable subtasks for greater quality and control.
How to improve LLM latency?
Improving LLM latency can be achieved through:
Prompt caching: Place repetitive elements or standard instructions at the beginning of prompts, enabling quicker processing through cached responses.
Utilizing predicted outputs: Leverage features like OpenAI’s “predicted outputs,” which pre-generate responses when subsequent tokens are predictable, significantly reducing response time, especially for minor adjustments in repeated tasks.
author(s)

Simon Palstermans
Machine Learning Engineer