disclaimer
This article reflects earlier work at Superlinear.
Our focus has since narrowed and deepened toward enterprise-wide orchestration to remove structural productivity bottlenecks across complex organizations. Today, we focus on long-term operational performance in mission-critical European industries.
To understand how we approach this now, visit our homepage.

Article
The rise of Large Language Models (LLMs) and AI has brought Retrieval-Augmented Generation (RAG) systems into the spotlight. These systems enhance LLM outputs by referencing an external, authoritative knowledge base, reducing hallucinations and improving contextual accuracy.
While traditional RAG systems focus solely on text-based retrieval, the demand for richer, more precise responses is driving innovation toward Multimodal RAG systems. By leveraging various data types—text, images, videos, audio, and tables—these advanced systems provide a broader context, making them indispensable in fields like healthcare and finance.
But integrating diverse data sources into a single RAG system isn't straightforward. It involves challenges like effective storage, embedding of these formats, and ensuring the model accesses the appropriate modality. Let’s explore the current standards for Multimodal Retrieval-Augmented Generation (MRAG) and what the future might look like in the field of RAGs.
Why multimodal RAG?
Traditional RAG pipelines retrieve relevant text-based chunks to answer a query, generating contextually appropriate responses. However, limiting inputs and outputs to text alone can leave gaps in addressing certain questions. Imagine analyzing a company's financial performance, where vital data is often presented in charts, tables, or diagrams. Here, Multimodal RAG steps in.
Consider a page from the 2024 NVIDIA annual report (img 1a). To answer queries like, “How many board nominees are under 60 years old?” or “How many have financial expertise?” the system must process data from tables, text, and even images. This capability is what sets Multimodal RAGs apart from traditional text-based systems. (img 1b)

Img 1a: Financial document from annual NVIDIA report. The page contain information about new nominees for the NVIDIA board

Img 1b: Answering specific questions related to the nominees requires understanding of all the different modalities in the page
How do text-based RAG systems work?
Understanding traditional text-based RAGs provides a foundation for incorporating multimodal elements. A typical text RAG pipeline works as follows:
Document chunking: Splitting datasets into manageable text chunks.
Embedding chunks: Converting each chunk into numerical embeddings that capture semantic meaning.
Vector storage: Storing embeddings in a vector database for efficient retrieval.
Query processing: Transforming user queries into embeddings.
Similarity search: Retrieving the top-N relevant chunks based on query similarity.
Answer generation: Using retrieved chunks to generate a response.
This structured process forms the backbone of Multimodal RAG systems.

Img 2: Schematic representation of a text based RAG system
RAG systems are essential to allow you to chat with your data — see how GPT-4 makes it possible in this article.
Text is all you need
The most common strategy for integrating multimodal data is converting all inputs into text. This process is called text-grounding and involves generating textual descriptions for each modality and embedding these along with traditional text in the vector database. These embeddings then act as pointers to the original data that is retrieved every time a user questions references back to information contained in one of these descriptions. A schematic representation of this system is visible below (img 3).

Img 3: Schematic representation of a multimodal RAG system. Purple components highlight the differences with traditional text-based RAGs. It is important to notice how both questions and chunks can be grounded to text depending on how the system is set up.
Some examples of modality-to-text conversion techniques could be:
Modality | Conversion method |
|---|---|
🗣️ Audio | Transcription models like Whisper generate text from audio; diarization can be used to identify individual speakers. |
🖼️ Images | Multimodal LLMs such as GPT-4v or Gemini describe image content. For budget-friendly options, open-source models like CLIP can suffice. |
📊 Charts | Multimodal LLMs can still provide accurate descriptions from well-crafted prompts; Alternatively specialized models like Google’s DePlot can provide precise textual descriptions. |
🔢 Tables | OCR techniques and Multimodal LLMs effectively structure and describe tabular data. |
While specific cases may still require specialized solutions, the field is progressing toward a future where a single, highly capable multimodal model could handle the majority of text-grounding tasks.
Unstructured data can thus be systematically transformed into actionable text, along with other ways GenAI can exploit it to build business intelligence.
Is text-grounding the only option?
While text remains the preferred modality for embedding, other approaches, like creating a multimodal vector store, are technically feasible. However, this method comes with challenges:
Challenges of multimodal embedding
Limited options: Currently, widely adopted, high-performing multimodal embedding models are scarce. Some models, such as CLIP, handle specific modality pairs (e.g., text and images), but their scope is limited. Others, like ColiPali, specialized in a single embedding of both text & visuals, but their use is still very experimental. Relying on such models for a multimodal vector store may restrict future development and lead to suboptimal retrieval results.
Complexity of embeddings: Certain modalities, like images, are inherently complex. Images can be interpreted in various ways, including their pure content, object relationships, colors, style, correlations, or actions. An effective embedding must capture all of this information and be positioned within the embedding space to align with the diverse questions that could be posed. While it's possible to achieve this, the training is hard to accomplish.
Benefits of text-grounding
Higher information granularity: Asking targeted questions to an MLLM enables detailed exploration of the data. These questions generate different tags and descriptions that can act as anchors in the embedding space for better retrieval accuracy. For instance:
Modality | Possible extractions |
|---|---|
🗣️ Audio | Transcription, duration, tone, or participant details (e.g., age, accent). |
🖼️ Images | Type (e.g., chart, pictures), contained text, lighting, people, objects |
Advanced retrieval techniques: Well-tested methods from text-based retrieval, such as Hybrid Search or Late Interaction (ColBERT), can be exploited to enhance the system accuracy.
Recent advancements, like Meta's ImageBind, Apple’s 4M, or Microsoft’s Florence-2 hint at a future where multimodal embeddings could streamline RAG systems. For now, text-grounding remains the most practical approach.
Building a multimodal RAG system: a practical guide
Now that we’ve clarified how grounding to text is the current go-to strategy, let’s dive into how a multimodal pipeline would function in practice. The process involves two key stages: building the knowledge base and querying it.
1. Building the knowledge base
Using the NVIDIA annual report as an example, constructing a multimodal knowledge base involves:
Data separation: Splitting inputs by modality (e.g., text, images, audio).
Chunking: For complex formats like PDFs, frameworks like Superlinear RAGlite, Unstructured, or LayoutLM can be used to extract text chunks, tables, and images.
Embedding: Text is divided into chunks and embedded using an embedding model, other modalities are converted to text and embedded using the same text models. If the generated text is lengthy, it can be further chunked, with each chunk provided with proper context before embedding. The original modality is stored separately in an object store, and each text embedding is linked back to it.
A visual representation of this process can be seen in img 4, while img 5 shows an example of pdf chunking.

Img 4: Flow of multimodal documents in the creation of a multimodal knowledge base. Orange steps utilise AI components.

Img 5: A combination of the Unstructured and PyMuPDF extracts the table and the plots in the page as two separate images and the paragraph in the center as text
2. Querying the knowledge base
When a user submits a question:
Embed the query: Transform the query into embeddings, using the same embedding models and techniques used while building the knowledge base.
Search and retrieve: Locate matching embeddings in the vector store.
Rerank results: Prioritize chunks for the LLM to generate an accurate response via a reranking model.
Process modalities: Since retrieved chunks may originate from various modalities, route retrieved chunks to their original modality.
MLLM inference: Combine the retrieved chunks with the original query and feed it to the MLLM to generate a response.
A visual representation of this process can be seen in Img 6.
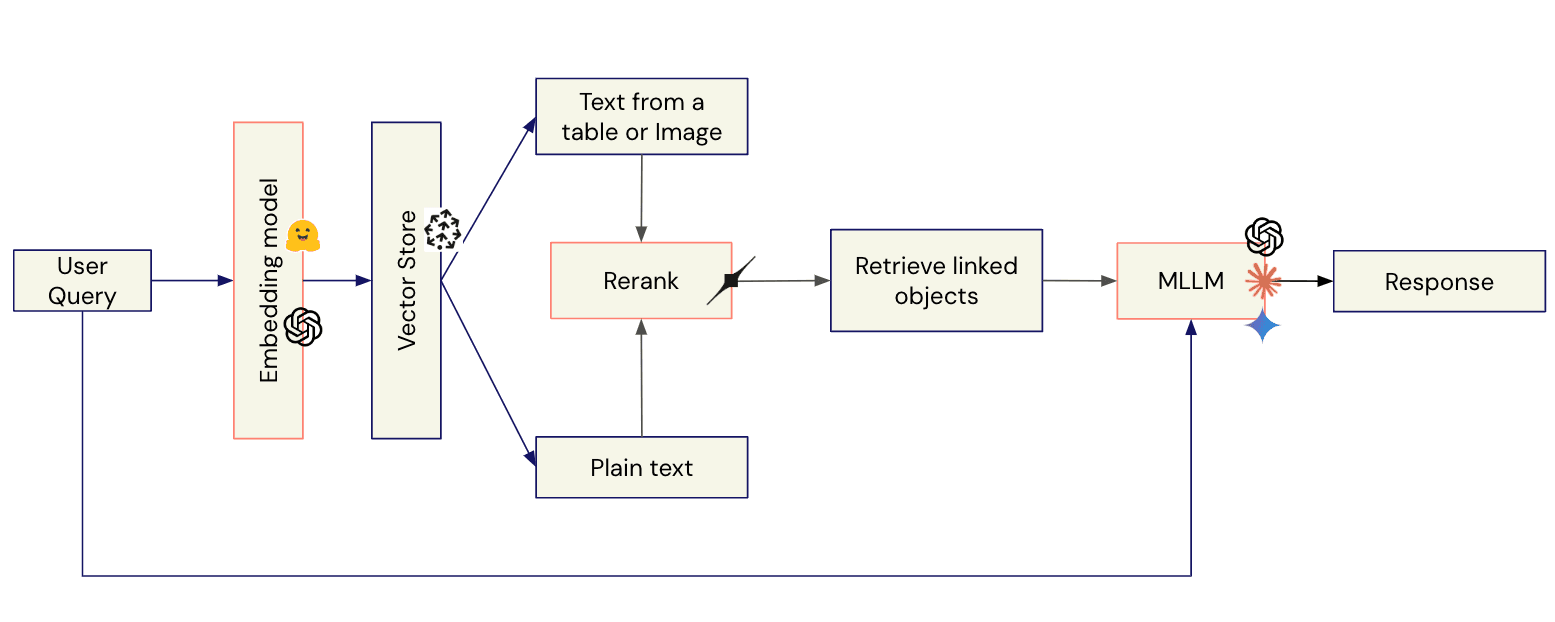
Img 6: Flow of user queries in the answering pipeline. Orange steps utilize AI components.
This step-by-step pipeline ensures precise, multimodal answers. As with any advanced AI implementation, incorporating MLOps is essential to ensure streamlined operations and scalability. If interested, you can find more about this in maximize your AI potential with MLOps.
Conclusions
Multimodal Retrieval-Augmented Generation (RAG) is transforming how AI systems handle complex queries, leveraging diverse data types to provide richer, contextually accurate responses. While text-grounding dominates today, advancements in multimodal embedding could soon simplify this process, enabling more seamless integration of non-text data.
FAQs about Multimodal RAG
1. What is Multimodal RAG?
Multimodal RAG (Retrieval Augmented Generation) is a system that retrieves and processes data from multiple modalities like text, images, and audio to enhance AI responses.
2. How does text-grounding work in RAG?
Text-grounding converts diverse data into text, embedding it into a vector store to enable retrieval and context generation.
3. Are there alternatives to text-grounding in RAG?
Yes, multimodal embedding models like CLIP or ColiPali offer alternatives, though they remain limited in scope or robustness.
4. What are the key challenges in building a Multimodal RAG?
Challenges include embedding diverse modalities effectively, ensuring scalability, and maintaining system accuracy.
5. Which industries benefit most from Multimodal RAG?
Healthcare, or finance can benefit from leveraging Multimodal RAG to integrate text, images, and tables for deeper insights.
author(s)

Mattia Molon
Computer Vision Team Lead & Machine Learning Engineer