
Article
At Superlinear, we often need to build full-stack POCs and applications. A small but effective REST API is often a vital part of such applications: we use an API to connect the front end to the machine learning back end, for example. Alternatively, we create and serve an API to our backend for the customer. This tutorial will explain the tools that we use to deploy APIs at a blazing speed which allows us to stay agile. Whether you’re a machine learning engineer, data scientist, data engineer or even still a student, this tutorial will definitely help you stay agile too.
We will take three steps to build and deploy a powerful REST API swiftly:
Design a simple and fast API with FastAPI
Create a Docker image containing our new API for fast serving
Write a Terraform script that enables automated deployments to AWS (or some other cloud provider)
Our running example in this tutorial will be a simple machine learning application that tries to predict house prices based on their location, their size (in m2) and the number of bedrooms they have. Everyone who has dabbled in machine learning before will probably recognise this textbook example. For simplicity, we will assume that we already have a state-of-the-art prediction model that is ready to predict some prices. We have created a small Python script that will create such a model for you.
Designing and writing our API using FastAPI
FastAPI is a blazingly fast (nomen est omen) open-source web framework written in Python. It can be used to write a complete REST API in minutes, including input and output validation, security, and automatic documentation. You guessed it: the engineers at Superlinear love FastAPI for its simplicity and power.
Let’s get right into it and discuss the battle plan for writing our API:
Set up our project.
Implement a GET endpoint that simply returns “Hello world!”.
At this point, we can already show some results, so let’s serve our API using uvicorn.
We will add a POST endpoint that can make predictions, the stuff we came here for.
Test our endpoint using the docs that are automatically generated by FastAPI.
Implement very basic data validation.
Setting up our project
First up, we will install FastAPI on our local machine. You can install it with pip, conda or even poetry. For the purpose of this tutorial, we will keep it simple and use good old pip, but feel free to use whatever package manager you’d like. We will also immediately install uvicorn to be able to serve and test our REST API locally.
$ pip install fastapi uvicorn
Let’s create our folder structure and populate it with our (for now empty) Python file. Let’s say we work in the my_first_api folder. Our folder structure will then look something like this:
my_first_api/
└── app/
├── __init__.py
├── main.py
└── models/
└── sota_model.joblib
All files belonging to our API will be put in the app/ folder, including the files belonging to our model. Other files, like a README.md or a Dockerfile (keep on reading!) will be placed one folder up, in the my_first_api folder. This will help us keep the API nicely separated. Now, let’s put some code in that Python file.
Our very first API endpoint in FastAPI
This tutorial assumes that you at least have some experience with Python, so we will skip explaining how you can import FastAPI. Let’s start with the most basic API you can build:
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"API status": "Hello World!"}
Let’s go over this simple piece of code:
On line 3, we create an instance of the FastAPI class. This instance will be used all over our Python file to interact with FastAPI. The first time we do that is on line 5, but let’s first look at the function we defined.
If you ignore FastAPI for a second, calling the read_root() function on line 6 would simply return a simple Python dict with some strings. Very easy!
The decorator right above the function definition tells FastAPI that our function corresponds to the path "/" with a GET operation. By putting that decorator on our function, FastAPI knows that when someone tries to GET the root (i.e. "http://example.com") of our API, it has to return the output of the read_root() function. Pretty straightforward, right?
Using uvicorn to serve the endpoint
Let’s see what we’ve created! For serving our very basic API, we will use uvicorn. Execute the following command to tell uvicorn to run the app object in our main.py file. The location of our main.py file is denoted by app.main as the file resides in the app/ folder. The --reload argument tells uvicorn to restart the server when it detects code changes and should only be used during development. You should run this command inside the my_first_api/ folder.
$ uvicorn app.main:app --reload
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [65020]
INFO: Started server process [65038]
INFO: Waiting for application startup.
INFO: Application startup complete.
The output of uvicorn tells you exactly what to do: you should go to http://127.0.0.1:8000 and see the API in its full glory! You should be able to see the output of our read_root() function being shown on the web page. This happens because your browser performed a GET request to the root of our API’s URL. And our API happily obliged and returned the output of the read_root() function back to our browser.
Exciting, right?!
Adding a POST endpoint
Let’s extend our super basic API by adding a POST endpoint that will predict the house prices. If that seems like a complex thing, see how easy FastAPI makes it look.
Let’s break this down:
On line 5, our state-of-the-art model is loaded using joblib (imported on line 2). This model has a function predict() that takes three arguments: the house’s location, size and number of bedrooms. It will return the house’s predicted price as a float.
On line 11, a decorator tells FastAPI that the corresponding function should be called when a user executes a POST operation on the "/predict/" path of our API. This path in full for our demo API is http://127.0.0.1:8000/predict/.
On line 12, we define a function that takes those same three arguments, passes them onto the model’s predict() function and returns the predicted price in a dict.
By adding that one line of decorator, FastAPI knows exactly what to do when it receives a POST request on the "/predict/" path. How it handles everything from getting the request and calling our predict_price() function is (thankfully) hidden from us. Since we don’t need to worry about that, this allows us to quickly set up a working and fast API in no time.
Trying out our API
Another handy feature of FastAPI is the automatic generation and availability of documentation about the API we designed. While running uvicorn, simply navigate your browser to http://127.0.0.1:8000/docs for the detailed documentation about the small piece of code we’ve just written. Take your time to familiarise yourself with the documentation.
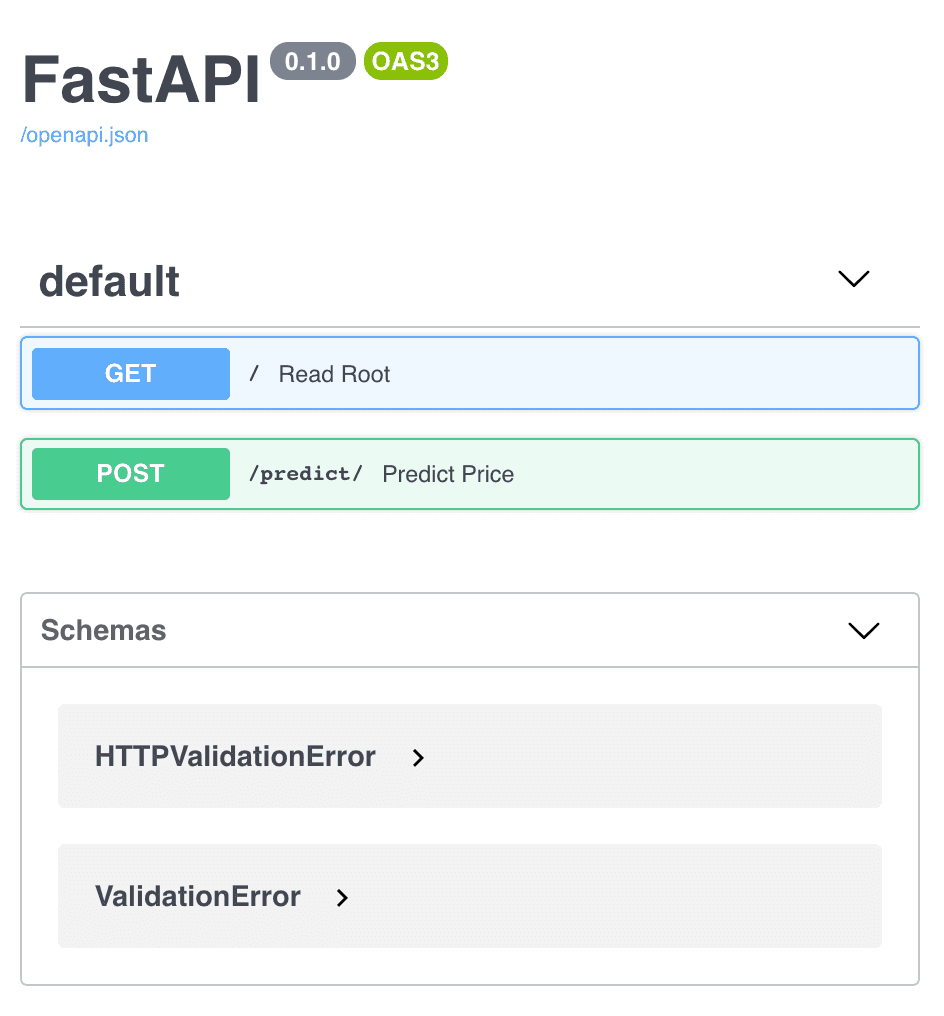
The main overview of our API's automatically generated documentation.
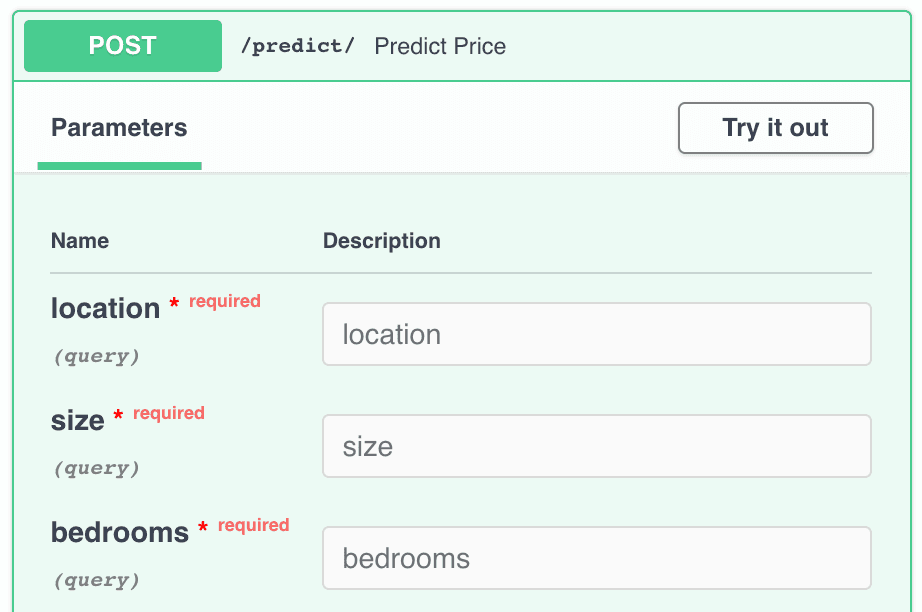
Part of the documentation about our prediction endpoint.
As you can see, FastAPI even included the parameters of our predict_price() function. It does this based on the code we wrote in our main.py file. The documentation also shows what the endpoint will return: an HTTP 200 code for a successful response, and an HTTP 422 in the case the given parameters are not in the correct format.
Another nice feature of FastAPI’s automatic documentation is that you can test out any statement in the browser! No need for curl in the command line: you can simply fill in the query’s parameters on the documentation page by clicking on "Try it out". Well, maybe you should try it out to see if your API is working correctly. Don’t forget to stress test the API: what happens when you leave a parameter blank?
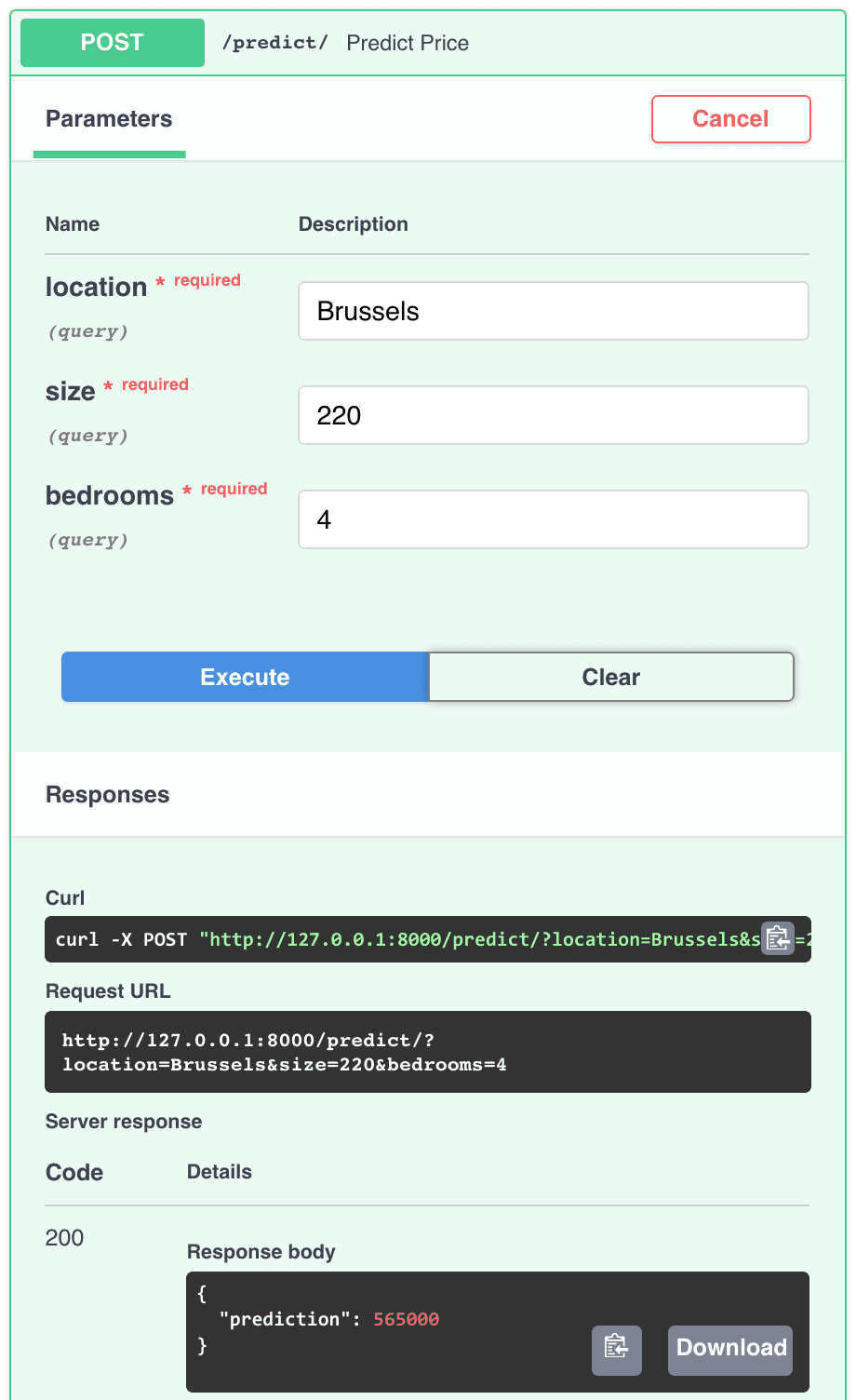
Testing out our API on the documentation web page.
Adding basic data validation
One last thing we will implement before creating our Docker image is simple data validation. Up until this point, we have simply declared three parameters for our predict_price() function. This means that those three parameters must be filled in in the POST request, but users can fill in whatever they want. For example, our API won’t complain if "392029" is filled in as the location, or "four" as the number of bedrooms. It will simply convert that "392029" string into an integer and pass it on as the location parameter to the model’s predict() function. At that point, something will go wrong in our code and a cryptic error will be shown to the user.
To stop those pesky users from entering wrong values on purpose, we can implement some straightforward data validation. In FastAPI, this is made possible by using type hints to define to what type an endpoint parameter belongs. For our example, we will tell FastAPI that the location is a string, the area of the house is a float, and the number of bedrooms is an integer. It’s possible to implement this surprisingly easy:
def predict_price(location: str, size: float, bedrooms: int):
...
These changes are immediately shown in the API’s documentation, go check it out. If a user now tries to input a string for the number of bedrooms, an HTTP 422 error will be shown with a clear explanation that the API expects to receive an integer instead of a string for that parameter. Push that "Try it out" button and try it out!
But let’s take the validation a step further. What about funny people who claim they have –25 bedrooms, or that they live in the city "" (empty string)? By using FastAPI's Query class, we can do some more advanced data validation on the query parameters that get passed to our API. You should set a Query instance to the default value of a parameter. Don’t worry about this strange syntax, FastAPI knows what it’s doing!
The Query class can have many different arguments, of which only the first one is required.
Let's go over some of the arguments you can add.
The first argument is always the default value for the query parameter. If you want a query parameter with a default value (e.g. by default 2 bedrooms), you can fill in that default value as the first argument. However, if you want to make the query parameter to be required to be filled in, the first argument should be an ellipsis (i.e. ...). In our code above, the location and size parameters are required to be filled in by the user. However, the user can omit the bedroom parameter: in that case, the default value of 2 is used.
Some arguments that you can add to the Query object will show more information in the documentation. For instance, the title and description of a parameter can be defined by the title and description arguments. In the example above, we added descriptions for each of the arguments.
And finally, other arguments will do some more fine-grained data validation on the query parameter. For example, you can demand that a number should be greater than or equal to 0 by using the ge argument. Or impose that a string should be at least 1 character long by using the argument min_length.
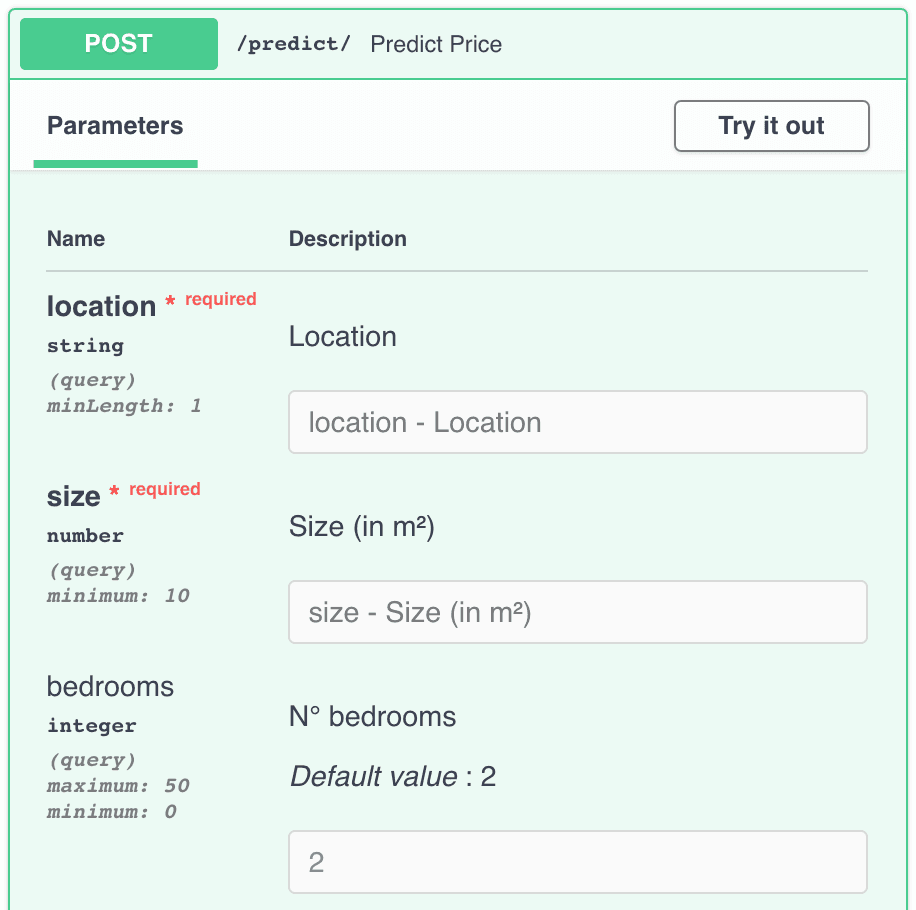
The final version of our API's documentation, including data validation and query descriptions.
Conclusion of FastAPI
The code snippet above is the final version of our concise but very effective API. By leveraging the power of FastAPI and uvicorn, we can do the following things:
Write a fully functional and very powerful REST API in minutes
Handle routing to the different endpoints
Perform simple and more advanced data validation
Display detailed and clear documentation
Test our API in the documentation
Swiftly serve the API using uvicorn
This tutorial is still too short to show the full potential of FastAPI. You can read FastAPI’s user guide to discover all of its features, including:
Out-of-the-box security, authentication and authorization
Path parameters that are part of the path (e.g. GET /user/{user_id}/)
Sending data in the request body
Cookie parameters
Sending files and/or forms
Support for many data types, including custom data types
Data validation on the data we return to the user
Even more powerful data validation using Pydantic
Concurrency
And many, many more
Running our API as a Docker container
Since its inception in 2013, Docker and its containers have taken over the software world by force, mainly because of Docker’s number one feature: maximizing the portability of a software application. By packaging your code and all of its dependencies in a self-sufficient Docker container, you can make sure that container works on almost every machine. It is not surprising that we at Superlinear also love Docker for exactly that reason.
This will be the shortest part of this tutorial, as can be seen from our TODO list:
A quick overview of Docker
Creating a Docker image
Running and testing our own Docker container
Before we start, make sure that you have installed Docker on your machine. If not, you can download it here. Once you get the Docker service running, you can continue with the tutorial.
A quick introduction to Docker
Launching a Docker container is child’s play. Simply run the following command, and you’ve got yourself running a Docker container containing the Ubuntu operating system in no time. It’s really that easy!
$ docker run --interactive --tty ubuntu /bin/bash
This command will first automatically download the latest version of the Ubuntu Docker image. It will then create a Docker container from that image and run the bash shell in that container. You can see the running Docker containers by running docker ps. And the command docker image ls shows all the images that you have downloaded to or build on your local machine. Now imagine if we can create our own Docker image that automatically starts our API.
Creating our own Docker image
And that’s exactly what we’re going to do! Luckily for us, the creator of FastAPI has already created a handy Docker image for us to use, called uvicorn-gunicorn-fastapi. That Docker image contains FastAPI and uvicorn, and will automatically serve every app object that is defined in the file /app/app/main.py when the container is booted. In other words, we will have to create our own image, based on uvicorn-gunicorn-fastapi, and declare that the files in our app/ folder should be copied to /app/app/. Note the difference between the app object (in main.py) and the app/ folder.
We define our Docker image in a Dockerfile (which has no file extension). That file contains our definition of the Docker image and will be used to create it. It will be placed in our root folder, which means that our folder structure will be like this:
That’s all! The first line says that our image will be based on the uvicorn-gunicorn-fastapi image. We will use the python3.8-slim version of that image. The slim suffix means that it uses a Linux version with only the bare minimum software installed (but including Python 3.8 of course). In the second line, we tell Docker to install the dependencies of our model using pip. And finally, the third line tells Docker to copy our app/ folder and its contents to the folder /app/app/ on the Docker image. From there on, the uvicorn-gunicorn-fastapi image will find our main.py and serve the app object inside using uvicorn. It’s that simple
There is only 1 step left before we can use our image: we need to build it from our Dockerfile. That’s done using the following command:
$ docker build --tag my-first-api-image .
The --tag argument tells Docker to name our image "my-first-api-image". The dot at the end of the command tells Docker that it should build the image in the current folder. From now on, it will be visible in the list you see when you run docker image ls. Now that the image is ready, it’s time for…
Running and testing our Docker image
As we’ve shown before in this tutorial, it’s very easy to run a Docker image as a container. We’re going to use a few more arguments than we’ve done when running the Ubuntu image though. The complete command we will use to run our Docker image is as follows:
Let’s go over all arguments one by one:
The --detach argument signifies that we want to run our Docker container in a detached state. This means that the container should run in the background. The ID of the container will be printed to the command line so that we can track it and refer to it. You can also find the container's ID by running docker ps.
The --name argument gives a name to our container.
We must publish the container’s ports to the host machine. This is needed as uvicorn will listen on port 80 for incoming requests. Because of --publish 80:80, all requests that the host machine receives on port 80 will be forwarded to uvicorn, also on port 80. Note that this is the default HTTP port.
The --env argument can be used to define environment variables for the Docker container to run in. In this case, we want to limit the number of uvicorn workers to 1 as we’re simply testing our application locally. In a production environment, it’s normal to have more than 1 worker running simultaneously to be able to handle larger loads.
And finally, we tell Docker which image to run.
We can verify that our Docker image is successfully running by navigating our browser to http://0.0.0.0/. Don’t forget to do this yourself to make sure that everything is working properly.
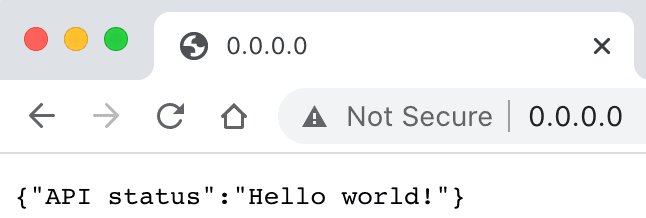
We're being greeted by our own API running in a Docker image!
Deploying our Docker image using Terraform
In the final part of this tutorial, we will explain how we can easily deploy our Docker image to any cloud platform using Terraform. As an example, this tutorial will deploy our API to AWS, but the techniques explained here can be applied to any other cloud provider.
We will deploy our Docker image in 4 steps:
Setting up Terraform
Creating a Docker repository on Amazon ECR and pushing our Docker image to it
Setting up the networking resources in AWS that we will need
Serving our Docker image using Amazon ECS and AWS Fargate
Let’s jump right into it!
Setting up Terraform
We are using Terraform 0.13.5. There are some syntactic differences between versions (e.g. Terraform 0.12 has a different provider syntax than version 0.13) so make sure that you install the correct version
Once you have installed the correct Terraform version, let’s start by creating a directory to put all our Terraform scripts in: infrastructure/. The mother of all Terraform files will be called main.tf, let’s create that one too. Once we’ve done this, our project structure will look as follows:
Note that only the app/ folder will be copied to our Docker image. The infrastructure/ folder and the Dockerfile are only used for deploying our API.
The first thing we’re going to do is defining the AWS provider in the main.tf file. By doing this, we tell Terraform that we want to deploy our infrastructure on AWS and that we will be using AWS-specific modules. More on that later. Defining the provider is done as follows.
The version definition seems a bit strange. The tilde and the greater than sign together (i.e. ~>) is called the pessimistic constraint operator. By using it, we tell Terraform to use the latest version of the 3.x release. Higher major versions, e.g. 4.x, will not be used.
Let’s configure the provider by telling it to what AWS region we want to deploy our application. We will use a new block for this. You can add a lot more arguments to the provider block, but all of them (including the region argument) are optional. You can find all possible arguments for the AWS provider here.
provider "aws" {
region = "eu-west-1"
}
Now we have enough code to initialise our Terraform infrastructure. Navigate to our infrastructure/ folder and run terraform init. If you’re not yet authenticated with AWS, now is the time to do so.
$ export AWS_ACCESS_KEY_ID="to be filled in"
$ export AWS_SECRET_ACCESS_KEY="to be filled in"
$ cd infrastructure
$ terraform init
Initializing the backend...
Initializing provider plugins...
- Finding hashicorp/aws versions matching "~> 3.0"...
- Installing hashicorp/aws v3.21.0...
- Installed hashicorp/aws v3.21.0 (signed by HashiCorp)
Terraform has created a lock file .terraform.lock.hcl to record the
provider selections it made above. Include this file in your version
control repository so that Terraform can guarantee to make the same
selections by default when you run "terraform init" in the future.
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan"
to see any changes that are required for your infrastructure. All
Terraform commands should now work.
If you ever set or change modules or backend configuration for
Terraform, rerun this command to reinitialize your working directory.
If you forget, other commands will detect it and remind you to do so
if necessary.
Now we’re ready to actually start adding AWS resources to our Terraform infrastructure!
Creating and using a Docker Registry
Let’s start with something simple: setting up a repository in Amazon ECR (Elastic Container Registry). We can then push our Docker image to the container registry, which allows us to pull our Docker image from anywhere in the world. Creating a repository in Terraform is surprisingly easy, we just need to add an ECR Repository resource block.
resource "aws_ecr_repository" "api_ecr" {
name = "prediction-api-repository"
}
Let’s explain what’s going on here. We define an aws_ecr_repository resource that we will refer to as api_ecr. This allows us to refer to the repository somewhere else in our Terraform code. We then add a single argument when creating the resource: the name of the resource (i.e. repository) in AWS. This is different from the Terraform name of the resource (although it could have the same value if you want).
Let’s see what we’ve done! Simply run terraform apply and Terraform will create our ECR Repository in seconds.
$ terraform apply
An execution plan has been generated and is shown below.
Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# aws_ecr_repository.api_ecr will be created
+ resource "aws_ecr_repository" "api_ecr" {
+ arn = (known after apply)
+ id = (known after apply)
+ image_tag_mutability = "MUTABLE"
+ name = "prediction-api-repository"
+ registry_id = (known after apply)
+ repository_url = (known after apply)
}
Plan: 1 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
aws_ecr_repository.api_ecr: Creating...
aws_ecr_repository.api_ecr: Creation complete after 1s
[id=prediction-api-repository]
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
We included the full output of the command here. As you can see, Terraform first shows you what it wants to do, in this case creating an ECR Repository. After checking the plan, you can then type "yes" to agree with that plan which allows Terraform to apply it. If you quickly want to check the current plan without accidentally applying it, the command terraform plan will only show the plan.
Let’s check out our newly created ECR Repository on AWS!
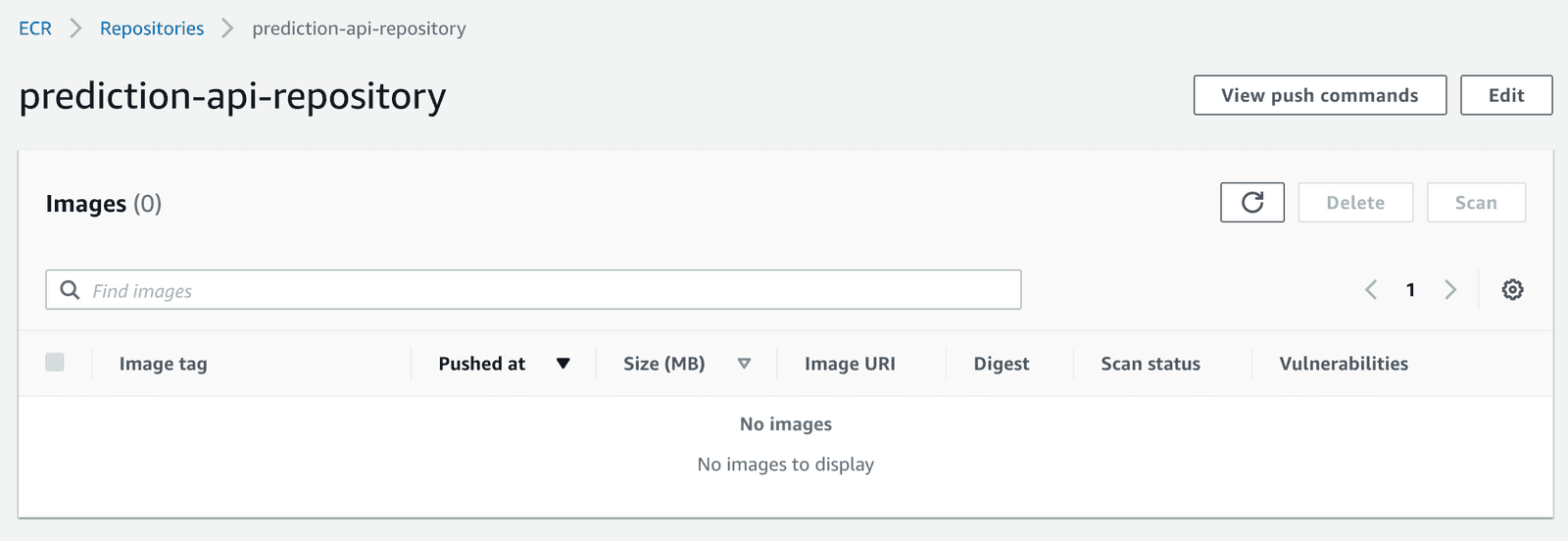
Our newly created ECR Repository. Empty for now.
As you can see, we don’t have any Docker images in it yet. Let’s change that by pushing our local image to the repository. The screenshot shows that AWS really wants to help you with that: if you click on “View push commands”, you can copy the 4 commands you need. Execute these commands in the root directory of your project.
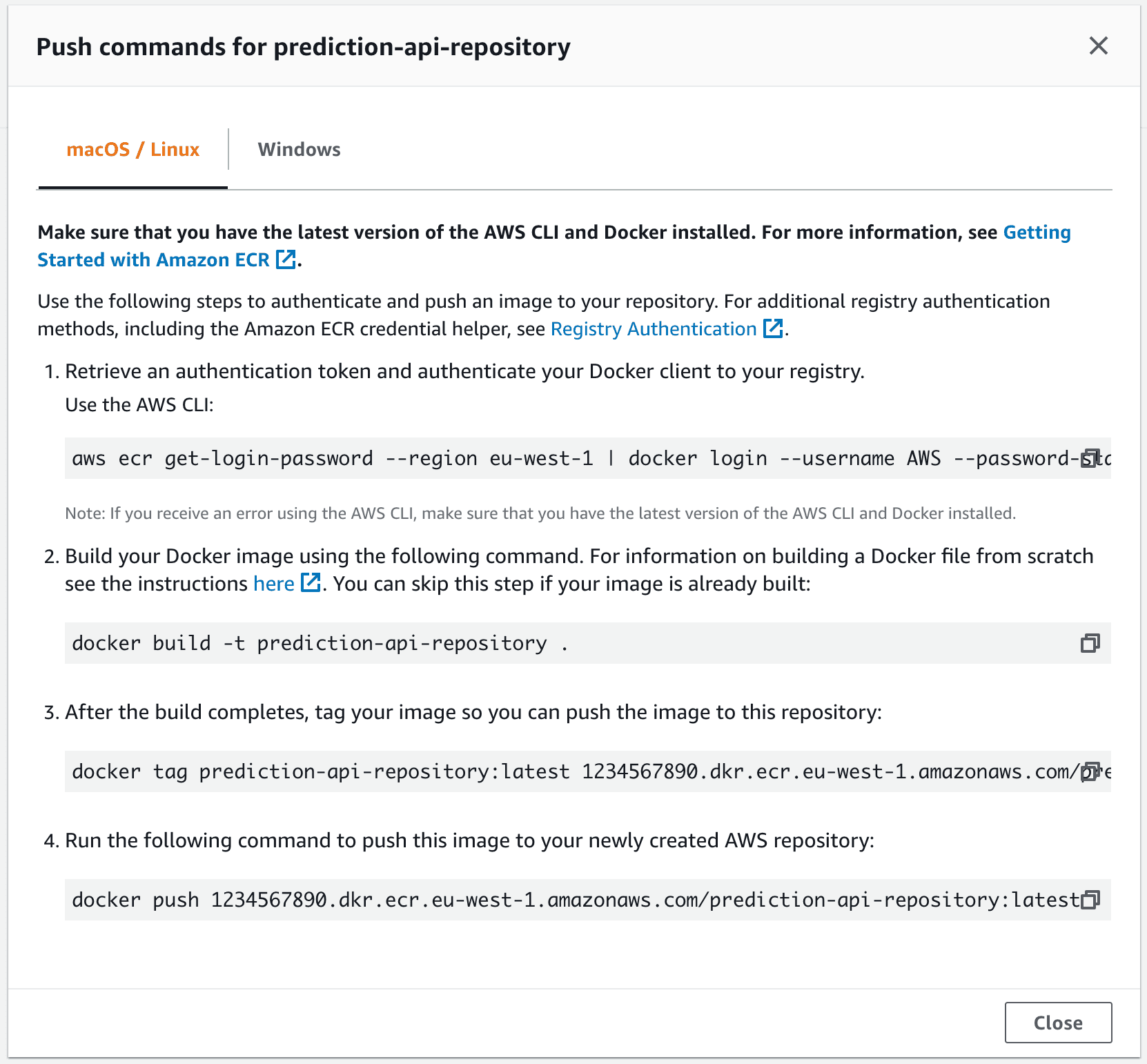
AWS makes it very easy to push your Docker image to the ECR repository by providing you with all the commands you need.
$ cd ..
$ aws ecr get-login-password --region eu-west-1 | docker login \\
--username AWS --password-stdin xxx.amazonaws.com
Login succeeded!
$ docker build -t prediction-api-repository .
...
Successfully built 282c1065b664
Successfully tagged prediction-api-repository:latest
$ docker tag prediction-api-repository:latest \\
xxx.amazonaws.com/prediction-api-repository:latest
$ docker push xxx.amazonaws.com/prediction-api-repository:latest
After pushing your Docker image to the ECR Repository, you will be able to view it there. And, more importantly, you will be able to pull it from anywhere you want!
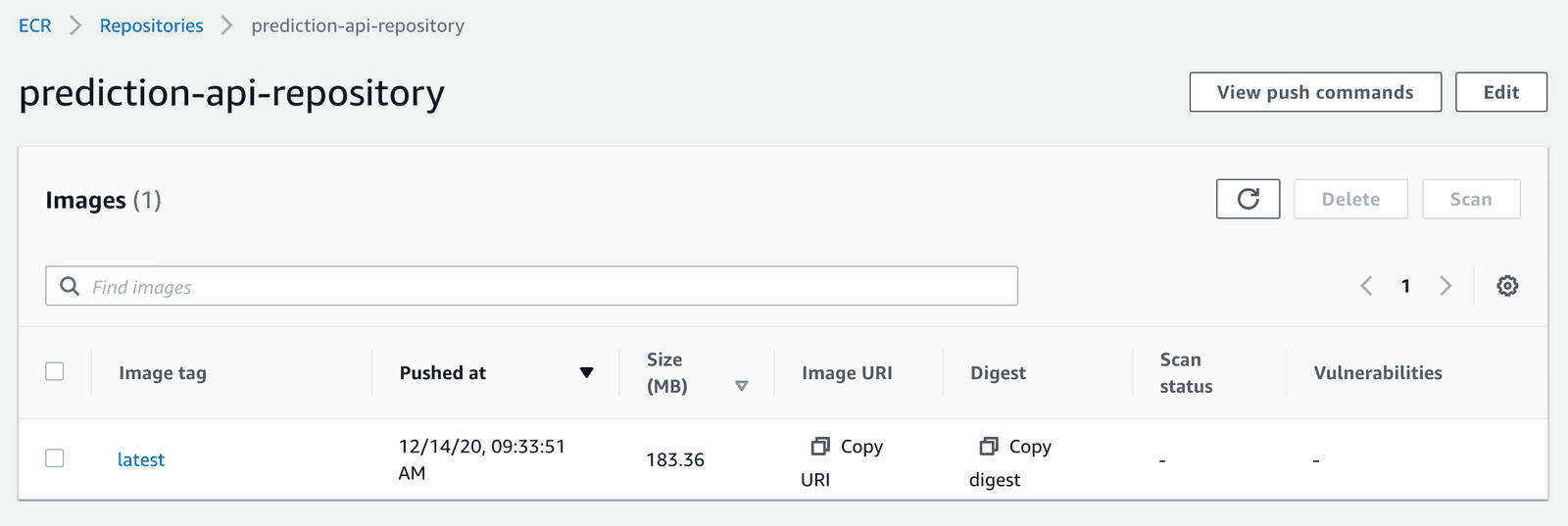
Our Docker image has made it into the ECR Repository!
Creating a nice networking environment for our container
I’d love to show you how to immediately serve your Docker image, but first, we need to set up a few more things. Those who have worked with AWS before know that you need to create a network to be able to do almost anything on AWS. Typically, we need to set up a VPC, subnets, an internet gateway, routing tables, security groups, a load balancer, listeners, target groups, health checks, policies ... We will also actually need to create those things, but with Terraform, it’s easy as a whistle!
By default, most AWS accounts have a default Virtual Private Cloud (VPC) in each region. On top of that, an associated Internet Gateway (IGW) and an associated security group are also present. Instead of creating these again, for this small demo application, we will use these default resources. We can either manually copy-paste the VPC, IGW and security group IDs to our Terraform scripts, or define them programmatically as Data Sources. We will opt for the latter.
For each of the things on our networking shopping list, we can use the associated Terraform resource, but sometimes it’s easier to not reinvent the wheel. People have already needed to set up a load balancer in a nice networking environment countless times before, so why not borrow from them? In Terraform it’s possible to put multiple resources and Terraform code into a module. These modules can then be reused, e.g. for staging and production environments. And people can also share those modules online. This makes it easier for us to write Terraform code because we can reuse modules that combine multiple resources into one.
For our application, I’ve selected a few modules made by the DevOps company Cloud Posse that will help us write our AWS infrastructure even faster. Let’s ease into it by first defining our existing data sources. Then, we will create the subnets with the help of Cloud Posse. After that, we create a security group, designed for web applications. And finally, we will add a (vanilla) load balancer to the setup.
Defining the existing data sources
While it’s very easy to create a new VPC and a new IGW in Terraform, we are opting to include the default ones as data sources into our infrastructure. We could simply copy-paste their IDs into Terraform, but that’s not as pretty and may introduce mistakes. The first one is the default VPC. It’s really as simple as writing the following three lines.
data "aws_vpc" "default" {
default = true
}
Defining the default Internet Gateway is almost as simple. We will define it by filtering over all IGWs in the region and choosing the one connected to our VPC. This will also immediately show you how easy it is to refer to our VPC.
data "aws_internet_gateway" "default" {
filter {
name = "attachment.vpc-id"
values = [data.aws_vpc.default.id]
}
}
Note that we name each of these data sources "default". This is by our own choice. We can also name these "default_vpc" for instance. We would then need to refer to its ID as data.aws_vpc.default_vpc.id.
Creating the subnets
For our subnets, we will use the AWS Dynamics Subnets module by Cloud Posse. You should copy the block of code under the Usage header on the linked GitHub page (be sure to pin to a release tag). Next, you should fill in the arguments provided. Down the page, there is a detailed list of all the arguments that you can provide.
module "subnets" {
source = "git::https://github.com/cloudposse/terraform-aws-dynamic-subnets.git?ref=tags/0.32.0"
namespace = "rdx"
stage = "dev"
name = "prediction-api"
vpc_id = data.aws_vpc.default.id
igw_id = data.aws_internet_gateway.default.id
cidr_block = "10.0.2.0/24"
availability_zones = ["eu-west-1a", "eu-west-1b", "eu-west-1c"]
}
The source argument is required because it tells Terraform where the module is defined. The next three arguments are optional but it’s nice to include them as they will be used to give a nice name to our subnets, in our case "rdx-dev-prediction-api". We have the VPC and IGW defined as data sources so they’re easy to fill in. For the CIDR block, you can choose any IP range that falls within the private IP ranges. And finally, you can add all availability zones that are available in your AWS Region to the availability zones argument.
That’s all we need to define our subnets. We can now refer to them in other parts of our Terraform code, e.g. module.subnets.public_subnet_ids.
Creating a simple security group
Cloud Posse is not the only provider of modules. Terraform themselves also provide many modules, like a simple security group module, made specifically for web connections (i.e. using port 80). The arguments for this module are not difficult to decipher. Except for the last one: that argument means that we accept connections from any IP address.
module "security_group" {
source = "terraform-aws-modules/security-group/aws//modules/http-80"
name = "prediction-api-sg"
vpc_id = data.aws_vpc.default.id
ingress_cidr_blocks = ["0.0.0.0/0"]
}
Defining the load balancer
With our VPC and subnets defined, we can add an Application Load Balancer (ALB) to the mix. By using an ALB, we can put our container behind a single URL, even when it gets redeployed or when it needs to be restarted for some reason. It also helps to redirect traffic throughout our VPC and subnets. We will be using an ALB module provided by Terraform itself for this part.
We used the minimum number of arguments here, please feel free to look at the Terraform documentation if you want to change some default values. We again define the source code of this module, and also the version. Once that’s out of the way, we begin with naming our resource. Because Terraform needs to know in which VPC and in which subnets it needs to add our ALB, we must also give those arguments. Note that we refer to the public subnets by referring to the module we created earlier. It also needs to know about the security group we created, because the security group will cover the ALB’s ports to only allow connections to port 80.
module "alb" {
source = "terraform-aws-modules/alb/aws"
version = "~> 5.0"
name = "prediction-api-alb"
vpc_id = data.aws_vpc.default.id
subnets = module.subnets.public_subnet_ids
security_groups = [module.security_group.this_security_group_id]
target_groups = [...] # we will fill this in later
http_tcp_listeners = [...] # we will fill this in later
}
As you can see, we didn’t fill in our target groups and listeners yet. A target group is used to route any requests the listeners receive to our Docker container. It is also used to health check whatever it is targeting (in this case our Docker container). What is not defined in our Terraform target group, is where the target group should redirect traffic to. More on that later. You can see that we define the health check path as "/docs". This means that the ALB will check whether our API is alive by trying to connect to our FastAPI documentation on port 80. If it gets an HTTP response in the range 200 to 399 (as defined in the matcher argument), everything is fine and dandy!
target_groups = [
{
name = "prediction-api-tg"
port = 80
protocol = "HTTP"
target_type = "ip"
vpc_id = data.aws_vpc.default.id
health_check = {
path = "/docs"
port = "80"
matcher = "200-399"
}
}
]
To finish our ALB, we also need to define our listeners. A listener process listens to some ports of the ALB and routes the requests to its registered targets. In this case, our listener redirects all traffic from port 80 to the first target group in our list of target groups.
http_tcp_listeners = [
{
port = 80
protocol = "HTTP"
target_group_index = 0
}
]
Seeing our networking resources in action
Let’s see the results of our hard work. We should first perform the terraform init command for Terraform to download all the new modules we’ve used. After that, it’s time for the real deal: running terraform apply!
$ terraform init
...
$ terraform apply
...
Plan: 31 to add, 0 to change, 0 to destroy.
...
Apply complete! Resources: 31 added, 0 changed, 0 destroyed.
Surely check out your AWS to see those shiny new subnets and the ALB!
Serverlessly serving our container
Now that we have the networking infrastructure, we can begin the final step of deploying our Terraform infrastructure. For that, we will use Amazon ECS (Elastic Container Service). As AWS eloquently states, ECS is a fully managed container orchestration service. We can use it to run ECS clusters using AWS Fargate, a serverless compute service that will allow us to run containers without thinking about provisioning servers.
ECS works pretty straightforward. First, we need to describe how Fargate needs to run our Docker image in a JSON file: this is an ECS Task. This task will then be run by an ECS Service which also takes care of it. Finally, an ECS Cluster is a logical grouping of services and tasks. In our case, we will need to create one task, one service, and one cluster. Easy!
First, we will set up our vanilla ECS cluster, which will be over before you know it. Then we will create the JSON container definition using a module by Cloud Posse. Finally, we will make the service that will run the task on the cluster using another Cloud Posse module.
Setting up a vanilla ECS Cluster
We only need to give the ECS Cluster a name. That’s it. Fun, right?
resource "aws_ecs_cluster" "cluster" {
name = "prediction-api-cluster"
}
Creating the JSON container definition
The container definition that we will create here, will be passed on as a JSON file from which an ECS Task will be made. We will again use a Terraform module created by Cloud Posse.
module "container_definition" {
source = "git::https://github.com/cloudposse/terraform-aws-ecs-container-definition.git?ref=tags/0.44.0"
container_name = "prediction-api-container"
container_image = "xxx.amazonaws.com/prediction-api-repository"
port_mappings = [
{
containerPort = 80
hostPort = 80
protocol = "tcp"
}
]
}
The most important arguments for this module are the last two. The container image argument contains the link to the Docker image in the ECR Repository. And the port mappings argument makes sure that all incoming requests to port 80 are forwarded to port 80 of the Docker container. Again, there are more arguments you can check out to adjust the container definition to your needs, including memory and CPU size.
Building the ECS Service
The ECS Service is the glue that binds it all together: it will create a task out of the JSON container definition and put it on the ECS Cluster. On top of that, it will also let the ALB know where to point its target group. Thanks for Cloud Posse for making that all seem easy by providing us with a nice template. This is the longest piece of Terraform code we’ll see in this tutorial, but by now, you should feel pretty confident about Terraform already.
module "ecs_alb_service_task" {
source = "git::https://github.com/cloudposse/terraform-aws-ecs-alb-service-task.git?ref=tags/0.40.2"
namespace = "rdx"
stage = "dev"
name = "prediction-api"
container_definition_json = module.container_definition.json_map_encoded_list
ecs_cluster_arn = aws_ecs_cluster.cluster.arn
launch_type = "FARGATE"
vpc_id = data.aws_vpc.default.id
security_group_ids = [module.security_group.this_security_group_id]
subnet_ids = module.subnets.public_subnet_ids
health_check_grace_period_seconds = 60
ignore_changes_task_definition = false
ecs_load_balancers = [
{
target_group_arn = module.alb.target_group_arns[0]
elb_name = ""
container_name = "prediction-api-container"
container_port = 80
}]
}
We will go over the important arguments one last time. We pass on our container definition to the service as a JSON file out of which a task will be made. We also make sure that the service knows about the cluster it needs to run in. The launch type of this service is AWS Fargate which will make sure that our container will be run serverless. Finally, we also point our service to the ALB in the final argument. Note that we leave the ELB name because it’s required, even though it’s not applicable to our application as we have no ELB.
And finally, deploying literally everything
You can run terraform init and terraform apply one last time. Once everything has been deployed by Terraform, you will be able to see every resource in AWS. If you want to see our API live in action, go to your newly created load balancer and check its DNS name. Once you follow that link, you will be able to see our beautiful API!
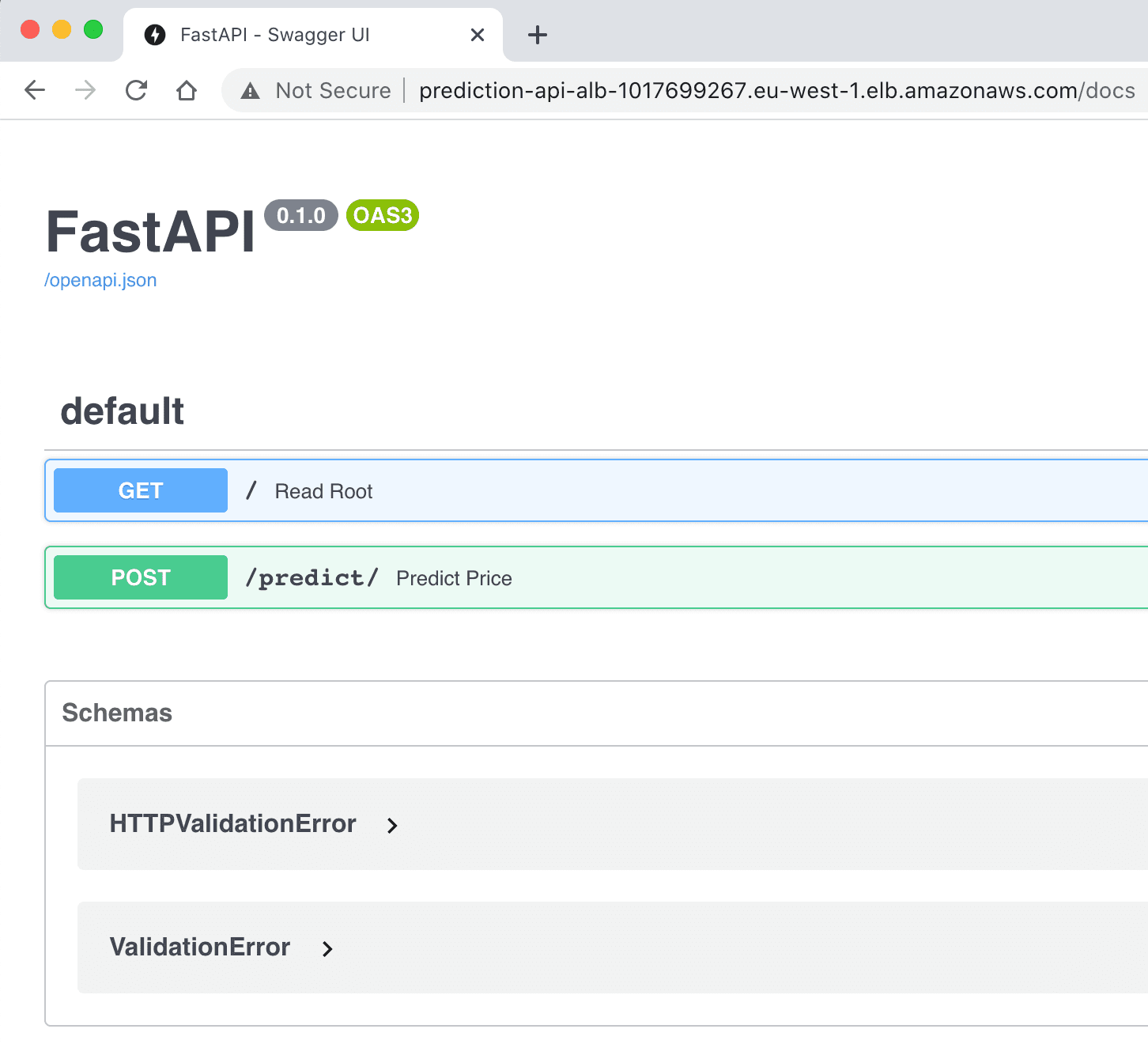
Our prediction API is live!
Terraform: Next steps
As you have seen, it’s pretty easy to set up a very simple ECS Service which runs your Docker container. Sadly enough, we have only touched the surface of the possibilities of Terraform. Luckily, Terraform themselves offer free tutorials which will explain everything into much more detail.
If you need a challenge, you could try improving your current Terraform set up with the following improvements. If you’ve had enough of our Prediction API, you can just keep these in mind for the next time you build a Terraform infrastructure.
Create a variables.tf file and a development.tfvars file which will allow you to use nicely defined variables in your main.tf instead of strings and integers everywhere. The former contains the variable definitions (that you can make yourself) while the latter file contains the actual values for those variables. This also allows you to create multiple .tfvars files, e.g. one per region or one per staging environment.
Try to make your API reachable by HTTPS. That’s much safer! To be able to reach your API by HTTPS, you need a certificate.
Put your prediction API behind a nice URL using Route 53.And before your main.tf gets too big, try to split it up into modules.
Wrapping it up
In this tutorial, we taught you how to write a concise REST API using the powerful FastAPI framework, serve that API using uvicorn, wrap it in a platform-agnostic Docker image, and finally deploying that image on AWS using Terraform. We only touched the surface of possibilities for all of these tools, but it’s enough to write a small API. Each of the tools we covered has very good guides that are more in-depth than we could possibly go in this tutorial. Nevertheless, we hope you learned something new and will use these tools more in the future.
author(s)
Giel Dops