disclaimer
This article reflects earlier work at Superlinear.
Our focus has since narrowed and deepened toward enterprise-wide orchestration to remove structural productivity bottlenecks across complex organizations. Today, we focus on long-term operational performance in mission-critical European industries.
To understand how we approach this now, visit our homepage.

Article
In many minds, Machine Learning is inevitably connected with having data. And although having heaps of ‘the new gold’ is indeed often an advantage when starting your AI project, it is not always necessary or even possible to have such amounts of data. It can be very complex or expensive to gather it, and your business might just not be ready for that yet. In this blog post, we’ll walk over some examples of how ML can be done with no or a minimal amount of data and what it can mean for you and your company.
Data... before or after?
As Machine Learning and AI became more and more popular in the last few decades, more and more use cases in the industry popped up and proved to be of enormous value. From ‘the early days’ of spam classification, over demand forecasting, to state-of-the-art applications such as using transformers trained on the entirety of Wikipedia for generating natural responses to customers or using Generative Adversarial Networks to upscale your images. A lot of these applications have in common that people had data lying around and wanted to make use of it. Fed by new AI technologies from research, applications were made based on the data available. If you look at it, it is a very natural way of growth in the AI field. I call this the data before approach and so, in other words, the application or algorithm after approach. As already said, this has proven itself to unlock massive potential with AI.
However, at Superlinear, we notice that thinking in terms of the data before approach limits companies in unlocking the full potential AI has for them. If the data is not there yet, some useful AI applications might not even be considered, and possible competitive advantages might not be uncovered. That is why the data after approach is often also a good perspective, and as Superlinear, we want to encourage every one of you to consider what AI can do for you without thinking of what data you have first!
You start with listing your business problems or potential use cases, you select the ones that might be solved with AI (if needed, involve an expert!) and only then you see if you have the right data, if it needs to be gathered and/or which structure or format it needs to have to solve your case. This process is how your company can build a structured AI strategy roadmap that will allow you to work towards improving your business instead of being limited by the data you have at this very moment. As you can guess, it often leads to thinking about Machine Learning without having data.. But, Why not?
ML with little data advancements
Of course, when you have the use cases you want to solve, still having to gather thousands to even sometimes hundreds of thousands of data points is not always feasible. Luckily, the AI field has had an exponential decrease in the amount of data needed to solve a problem. As already predicted in 2015 by Lecun, Bengio, and Hinton in their Nature Review, unsupervised, semi-supervised, and self-supervised learning approaches have gotten a lot of attention (For the more technical people, see what I did there? ;) ). I’ll give a brief but not complete list of advancements that made it possible to do ML with little or no data.
Transfer learning
We, humans, are good at learning new things if we have already learned something similar. If we know how a dog, horse, or cat looks, it will be easier to learn how to identify a donkey. That is because we learn lower-level concepts, f.e. Fur, paws, snout,... Machine learning algorithms actually show the same behavior. Let’s look at an example of car type classification. When first trained on a huge dataset of images, f.e. they learn low-level features such as corners, circles, stripes, etc. Then higher-level features such as windows, wheels, body,… If you use the same Neural Network to then learn to classify boats or trucks, it will be able to reuse a lot of its knowledge and require only a minimal amount of data.
Transfer learning is often used in combination with publicly available datasets. One good example is making use of Wikipedia to train the newest state-of-the-art Language Models. But also in your use cases, some similar data might be available to start learning from. And if that is not the case, you can even use simulated data!
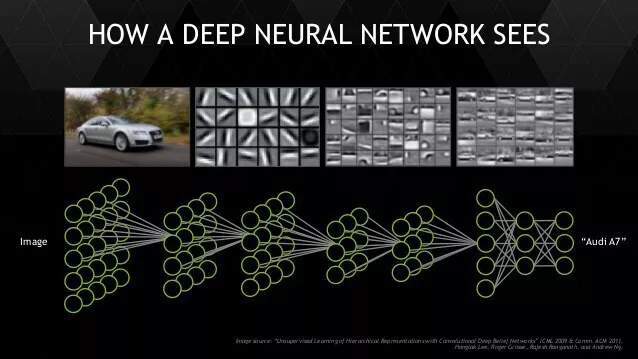
A neural network first learns low level-features and further in the network, it learns higher-level concepts. These features and concepts can be reused for other applications while needing fewer data examples.
Data augmentation
Who doesn’t like kittens, so what better way to explain data augmentation than to use kittens. Data augmentation is a technique where you use data points (f.e. Images of kittens) that are already labeled and do transformations on them. The assumption is that the label will not change by doing these transformations. Still, the image looks like a totally different combination of 1’s and 0’s and thus as a new learning opportunity to the model. These transformations can be rotations, scaling, adding noise etc for images, but it is also used in Natural Language Processing by using SOTA translating models to translate a sentence to another language and back, so small perturbations occur on it. One of the more advanced examples is using generative models to produce ‘new’ data points.

For us, this looks like almost the same picture of the same cat. For a ML model, this looks like a set of totally different images.
Unsupervised learning
Supervised learning uses labels to show your model what is good and wrong, and your model can learn from that. That is the most standard case of machine learning. However, some algorithms can find patterns in your data without even having labels. Unsupervised learning. The most known algorithms are clustering and anomaly detection. You can make use of it by finding groups of similar data points first and then see if these groups make sense and label the groups rather than labeling every data point. Say you have 5000 data points per group, I’d say that can save you a lot of effort!
Self-supervised learning
Self-supervised learning is also a hot topic in the AI world at this moment. Instead of getting labels provided by humans, the algorithm provides itself with labels. How? By making use of the data it already has. In NLP, for example, the model can look at a text, leave a word out, and try to predict the missing word based on its context. By doing that, it can learn structure in data, and this actually leads to the SOTA LMs that have taken a big step in the last years. These language models can then be used to do a downstream task such as question-answering or summarization based on limited sets of data.
Mix it up!
Each of the above advancements helps us to solve AI problems with less and less data. But the most interesting is the ability to combine all of those in creative ways to test Machine Learning with little data (or even no data) to its limits. One example is an algorithm called Unsupervised Data Augmentation. As the name suggests, it uses unlabeled data to learn from. The only assumption made is that the prediction of an original data point and a slightly augmented data point should be the same, regardless of the label it actually is. A simple assumption, but the resulting improvements can be enormous! In some cases, almost the same error rates can be reached with a factor of 1000 fewer labeled data points. Another State-of-the-art yet more complicated example of a semi-supervised approach is MixMatch!
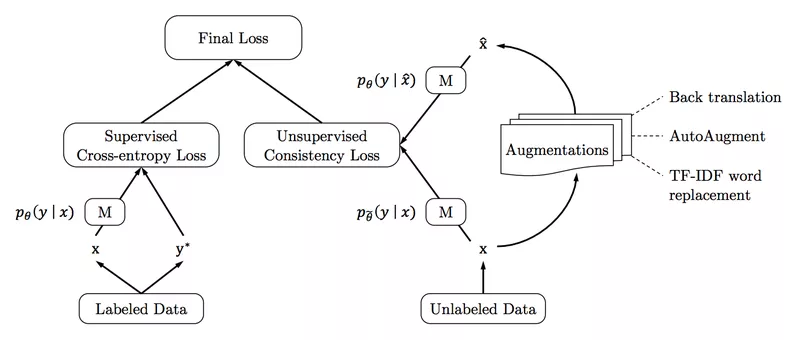
Unsupervised Data Augmentation: Similar error rates can be reached with up to a factor of 1000 less labeled images
And if all of the above does not help you solve your problem, you can look into posing your question slightly differently to use one of the ML with little data techniques. As the last example, imagine classifying 100 parts where you only have 5 examples per part. Even with transfer learning, five examples per class might prove to be insufficient. One way to maybe deal with this situation is to not ask the question “Which part is it?” from the start, but to ask, “Are these two images the same part or not?”. This transforms your dataset from 5 images for each class to each combination of 2 out of 500 (=125k). Using this, you might be able to extract more useful features, and you can then train a classifier on top.
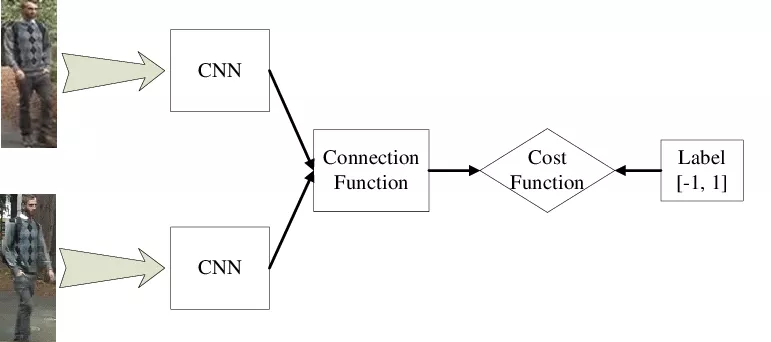
Take home message
Given all the recent advancements in machine learning with little data, you don’t need to be discouraged if you don’t immediately have the right data available. Instead, reflect on which of your use cases you might be able to tackle with AI and tackle the data aspect after. In that way, you can unlock the true potential of AI for your company. By being creative in the AI methods you use, you might be very surprised what you can achieve with only small efforts in your data!
If you might have some use cases worth looking into with AI but don’t know where to start or how to use your data most optimally, reach out, and we’ll be happy to find out together with you!
author(s)
Brecht Coghe