disclaimer
This article reflects earlier work at Superlinear.
Our focus has since narrowed and deepened toward enterprise-wide orchestration to remove structural productivity bottlenecks across complex organizations. Today, we focus on long-term operational performance in mission-critical European industries.
To understand how we approach this now, visit our homepage.

Article
"Serverless" is a very marketable term these days. When should you use serverless architecture and when should you not?
At Superlinear, we build software-as-a-service solutions that include AI components. For this task, serverless architectures give great benefits but come with limitations. So when does serverless make sense for AI?
What does serverless mean?
Before starting, let’s align on what is meant by a “serverless service” in this blogpost:
The service is managed by the cloud provider. On regular (non-serverless) services, it is your responsibility to install, maintain and administer the software or runtime. For a regular database service, for example, you have to install the database software, verify that it is up-to-date and patched, and set the configuration, so your database is working as smoothly as possible. A serverless database will take care of that for you, and simply allow you to connect and use the database without worrying.
The service only needs a limited amount of capacity provisioning management. On a regular service, it is your responsibility to increase the number of servers when the load is increasing. Let’s say your website becomes suddenly popular, you will have to manually increase the number of machines in your backend so that your website can stay up and running. A serverless backend will automatically increase the capacity if the number of requests is increasing.
When do we use serverless at Superlinear?
At Superlinear we use multiple serverless services: AWS Lambda for computational tasks, AWS DynamoDB for specific database use-cases, AWS S3 for general purpose storage, AWS Cognito for authentication and authorization, and more.
The space of cloud services is moving rapidly; yet, while the benefits of serverless services are heavily advertised, their limitations are not always so clear.
For us, the usual benefits of moving a workload to a serverless service are the following:
We do not have to pay when no one is using the service
The service scales (almost) as fast as the demand
No maintenance is needed at the cluster or the instance level
The limitations we faced when moving workloads to serverless are:
The dependencies: managing the source code
The internal state: loading and refreshing in-memory data
“Cold starts”: the first call to the service is slower
Let’s discuss AWS Lambda in particular. Lambdas already prove themselves useful for regular processing or monitoring tasks that are neither real-time nor involving artificial intelligence. But when does it make sense to use them when building a user-facing, real-time, Artificial
Intelligence infrastructure? Let’s compare two use cases.
A simple, stateless model is a great fit
Let’s say you have a Python machine learning model built using the scikit-learn library. It is modelling the number of people in a supermarket. It takes a hundred numerical features as input and will predict the number of customers that can be expected tomorrow.
Is this model a good candidate for a serverless architecture? Let’s discuss the limitations.
The dependencies
Our code might be dependent on the Pandas and Scikit-Learn libraries. These are heavy libraries that do not fit easily in an AWS Lambda. This is because they are heavy in size and because they rely on dynamic C libraries. This means that the library has to be compiled with AWS Lambda in mind.
Thankfully, some major libraries are already taken care of by projects like lambda-packs. If this is not the case for your library, a common technique is to compile the library in an environment that looks as-close-as-possible to the environment that the lambda is running on. For example, by using a Docker image specifically made for this purpose: lambci/lambda.
Size-wise, you should not go above 250MB of source code and binaries. (approx. 50MB when zipped)
Assuming you do not have libraries that are too heavy or that rely on C binaries, you can proceed.
The internal state
How much data does your code need to load before it can start making predictions? If you can fit your model as a file in the source code, you do not have to load anything before starting to compute predictions.
What about refreshing the state? Does your model need to re-train while being online? Does your model need to receive new data or new embeddings while running? Any complex state management will make it hard to use in an AWS Lambda.
In this case, we are working with a model loaded from a small file in the source code, and we do not need to retrain more than, let’s say, once a month. The deployment of the newly trained model can then be taken care of by replacing the model file in the source code and re-deploying.
Cold starts
Cold starts are a delay that can occur when a call is hitting a non-initialized lambda instance.
This is not an issue if the Lambda is used for non-real-time analytics or processing pipelines. However, when the Lambda is an API facing the user, this is not acceptable. Thankfully, AWS released an improvement in that space by allowing the provisioning of concurrency for AWS Lambda. Although this makes the Lambda less of a serverless service by our above definition, it definitely improves the experience of users of our API.
Good fit?
In summary, the model, the source code and the data are static and contained.
Inside a Lambda function, this will be ideal to respond to user requests quickly and with no added complexity.
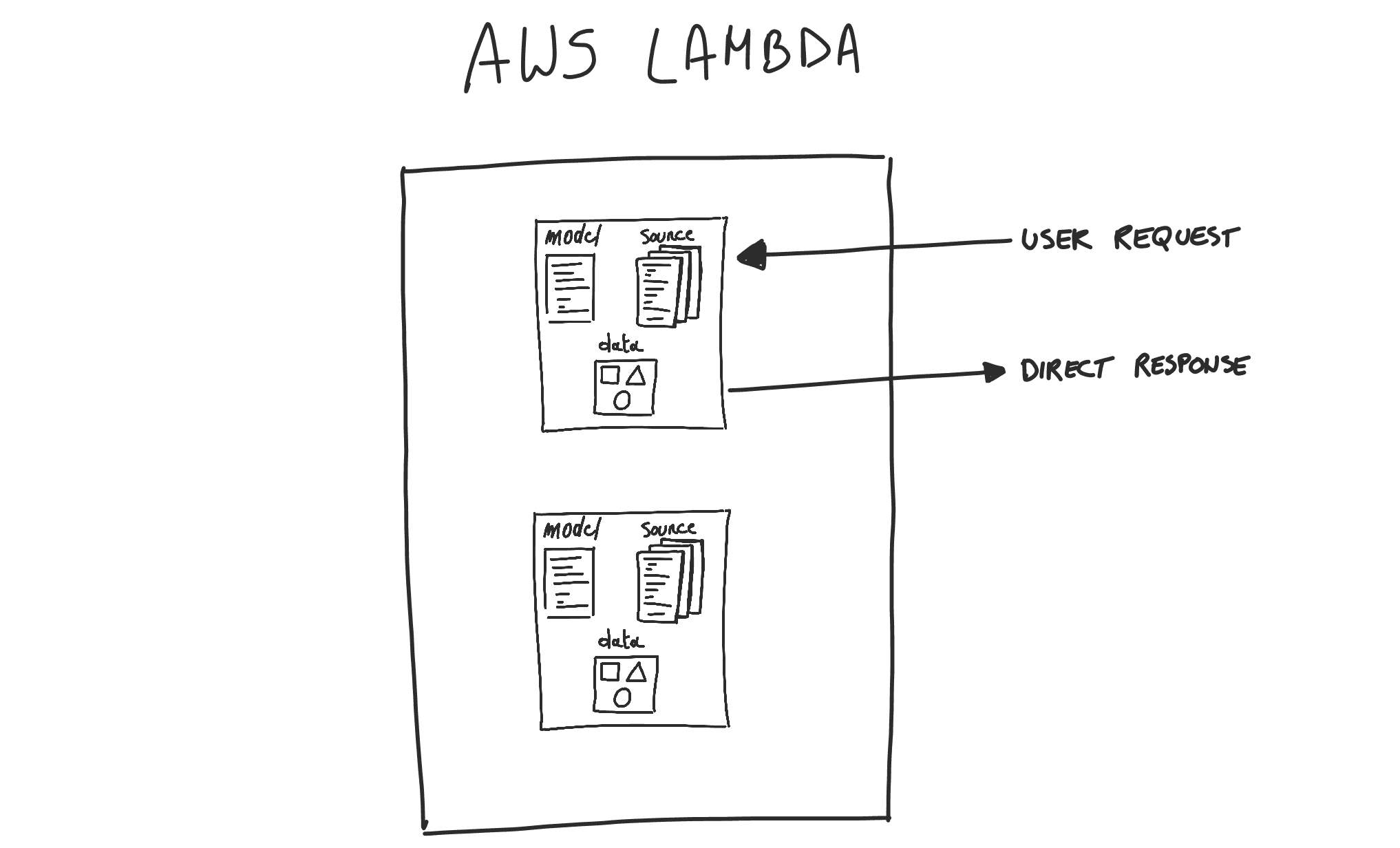
Our simple predictive model would be able to fit nicely in an AWS Lambda function!
This does not mean that this is the only and best solution. If scaling is not a requirement, a simple EC2 might make more sense. If AWS Sagemaker already covers your model out-of-the-box, this might be the more sensible solution. Have a look at my colleague’s blog post regarding Sagemaker.
A heavy, dynamic system is not a good fit
This time, you are building a recommender system for movies. It is an API that takes a user profile as input and gives a list of great movies to watch, specifically for that user.
You felt adventurous and built a system that relies on computing an embedding for each profile and an embedding for each movie.
If you don’t know what an embedding is or why it is useful, have a look at this article.
The API will work as follows: when a user is requesting the best movies to watch, the backend will compute the embedding that represents him based on his latest activity. Then this embedding will be compared to all the movie embeddings in order to find those that best fit his desires.
Are we still good for serverless?
The dependencies
What if your code depends on Tensorflow or any other big Machine Learning library? Zipped, Tensorflow is already almost 50MB, which is the limit for your source code size, compressed. This does not look good.
Additionally, these ML libraries often require to be compiled for certain CPU architecture or to run on a GPU. On AWS Lambda, you don’t have a choice of CPU and you can not access any GPU.
The internal state
When doing the recommendations, you need to have the embeddings for all the movies easily accessible. You could load them in memory when the lambda is starting, but:
The lambda will be slower to start.
Is your memory going to be enough if the catalog of movies increases in size? Will you have to add an in-memory data store like Redis on top of your AWS Lambda to have enough memory?
Additionally, how will you update the state when a new movie is added to the catalog? There is no good timing to do that in a serverless function.
Cold starts
If we are loading big amounts of data at startup, we now risk hitting even bigger cold starts. This can be fatal if the application is facing end-users.
Good fit?
The conclusion here is that this use-case is absolutely not fitting the serverless architecture. The source code is hard to fit, the model and the data need to be managed.
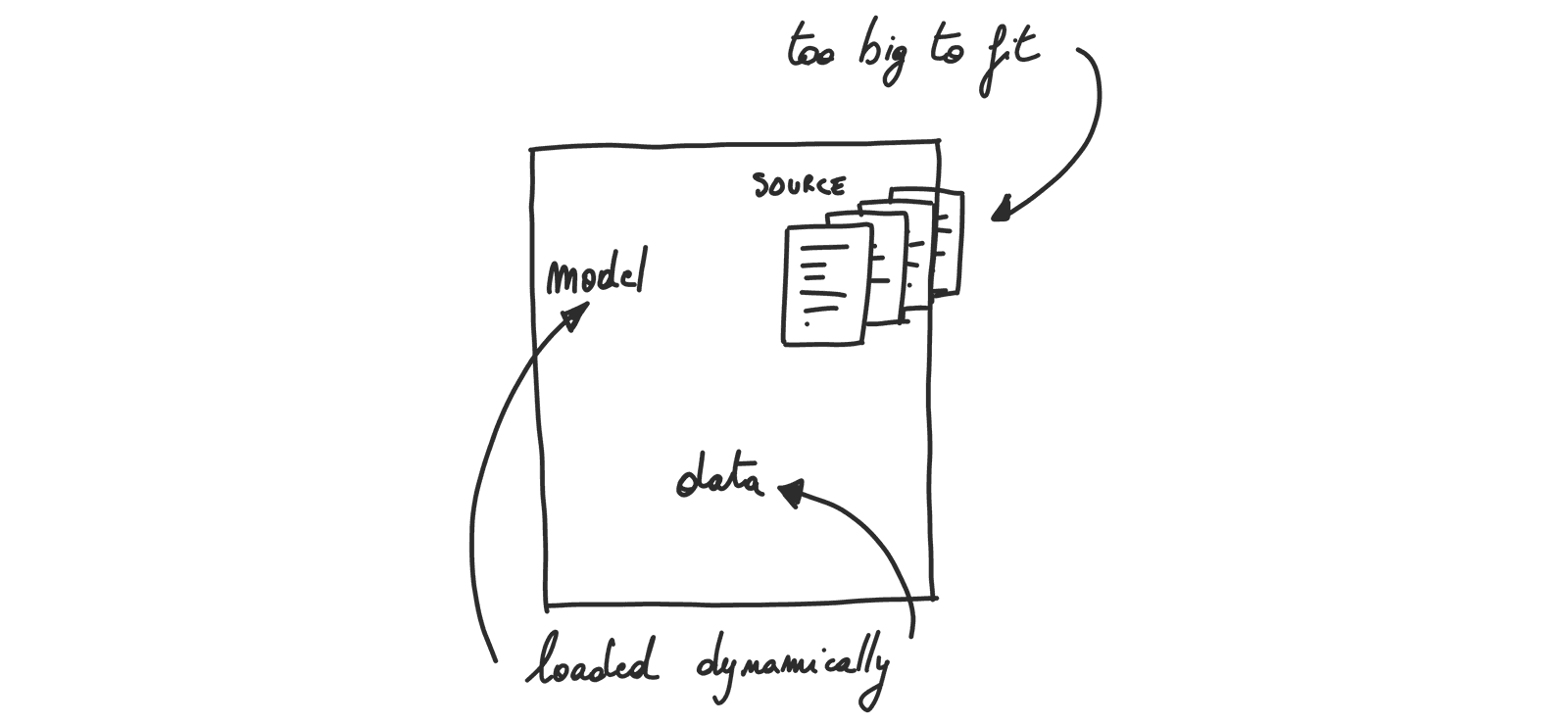
The source code, model and data are too big and change over time.
Forcing this model into an AWS Lambda would result in a lot of complexity in order to manage model loading and data updates. The user requests might not be satisfied in a short amount of time.
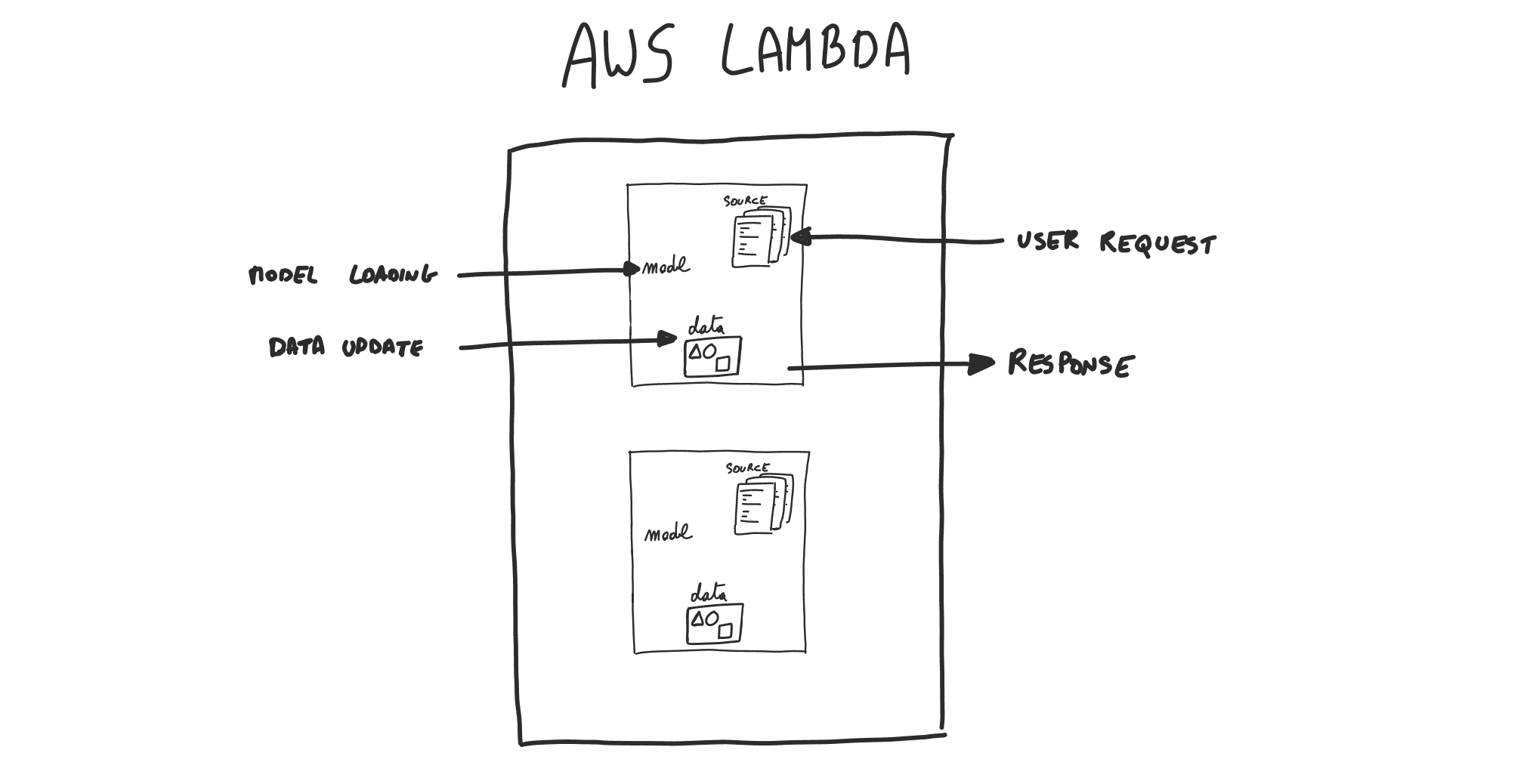
It's not ideal to have state management in a Lambda function.
Creating workarounds to make it fit will cost you more time than just accepting it and choosing a more adapted architecture.
Some other places to look for a solution in this case:
AWS Sagemaker. This can be a good solution if your model is supported, and the pricing is fitting your needs.
Elasticsearch. It is starting to support search in vector fields. This can be an excellent solution for storing and searching inside an embedding space.
AWS Fargate. It allows you to simply make a Docker available as a service. This can make state-management easier at the cost of less flexible scaling.
Conclusions
Hopefully, you now have a better overview of what is possible and not possible with the current state of serverless architectures on AWS.
Some models will be able to be served using a Lambda backend API. This can provide big advantages and peace of mind when serving many users.
However, when you can spot that your use case will exceed the limitations of what is possible on Lambdas, you should look for the same option.
author(s)
Rodolphe Cambier