
Imagine that you need powerful machines and scalability to perform parallel heavy backend calculations. You need these calculations to run within a strict time budget, and you don’t want to spend an unreasonable amount of money. We at Superlinear encountered such a problem and found that cloud batch processing worked best. While there is no magical solution to satisfy all those needs simultaneously, we’ll see in this blog post why Azure Batch is one of the ideal candidates to perform large-scale parallel batch workloads efficiently and with elasticity.
What is ‘heavy backend calculation’ and where you’d use it
Heavy backend calculations are essentially asynchronous parallel compute-intensive tasks that can run from minutes to hours and require more power than regular cloud solutions offer (both in terms of memory and cores). A typical example consists of a publicly exposed REST API where users send requests that trigger a numerically demanding calculation and come back later to fetch the expected result within the allotted time budget.
Here are several scenarios where you, as an engineer, perform heavy backend calculations:
Hyperparameter grid search in machine learning
Neural network training in deep learning
Searching for optimal solutions in operations research
Monte-Carlo simulations (risk simulation in the finance industry, sales forecasting, and others)
Image processing and rendering
And many more! Those scenarios lie in the so-called “embarrassingly parallel” paradigm, also referred to as loosely coupled parallel computations. While cloud batch computing provides a natural solution to those intrinsically parallel problems, it’s not limited to that paradigm. You also can use it for tightly coupled workloads, such as finite element simulations or fluid dynamics.
Whichever large-scale problem you’re facing, running it on the cloud while satisfying scalability, cost, and time constraints is a challenge.
Let’s see how batch computing helps us in that way through Azure Batch!
What is Azure Batch and how it can streamline your work
Azure Batch is a flexible solution that can scale depending on the needs from tens to thousands of compute nodes, each with a configuration to choose from among a vast array of virtual machines. Some of these machines (part of which come with a GPU) will suit almost all scenarios. It is also cost-efficient as there are no charges when no computer power is required.
For Batch itself, you pay only for the resources you use, which means you can control your budget. Last but not least, some available configurations support Docker, which allows us to run our containerized applications directly within Batch!
That’s nice, but how do you work with it?
Batch is made of several components. Let's get to know them.

Typical architecture using Azure Batch
The typical flow for a Batch calculation is the following:
Uploading data files that are needed for the calculations (if any), for example, different plannings to optimize if we think of operations research. The data storage most commonly used in pair with Azure Batch is Azure Blob Storage, although another data source (like Azure Data Lake Store, a SQL/NoSQL database, a redis cache, …) would work as well.
Creating and resizing a pool to match the specified number of nodes. If required, you can pull a custom Docker image from a container registry and load it on the node. This action comes with a small latency that depends on the needed configuration, so keep that in mind if time constraints are tight.
Creating the job and related tasks. Any required input is downloaded from the provided data source, including the Docker image (from the container registry) if it’s not already running on the node.
Monitoring the tasks during their execution, be it from the Azure Portal directly or from one of the APIs Microsoft provides. In case no node is available, pending tasks join the queue and wait for a node to be available.
Finished tasks upload their output to the provided data source.
The client downloads the results from the data source.
Need a visual summary? Let’s see the following chart:
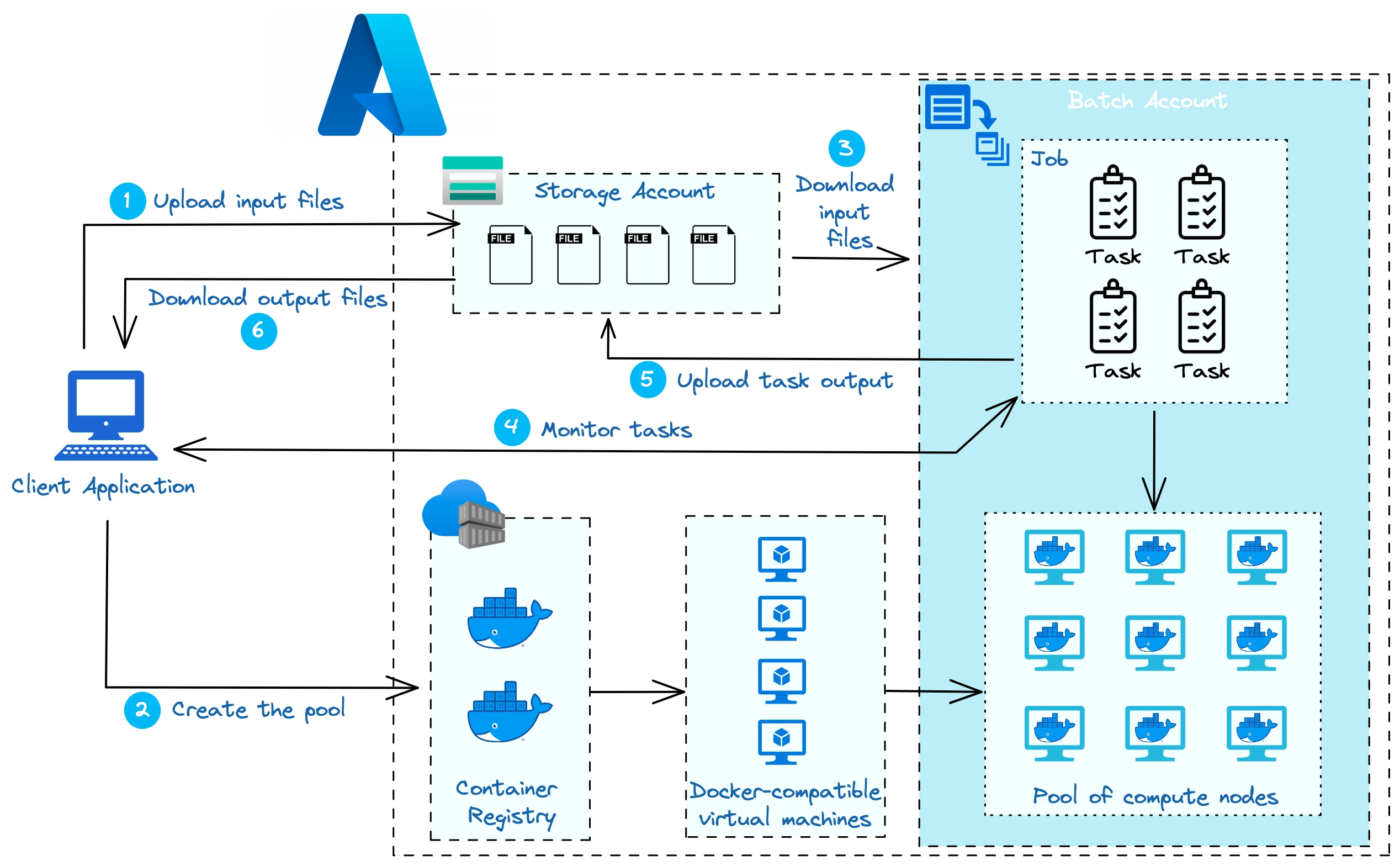
Although quite common, keep in mind that this workflow is not unique as one can, for instance, enable parallel task execution on one node in order to maximize the resource usage with fewer compute nodes.
Can you make your AI solution be more impactful with batch computing?
The short answer is: yes. Batch can efficiently serve your distributed workload because it can scale to thousands of powerful nodes, the most powerful configuration having 416 vCPUs and 11 400 Gb RAM as of writing those lines. It can provide a computing power that is difficult, not to say impossible, to gather on-premises. This allows saving a lot of time while sparing the burden of installing and managing a job scheduler. Thanks to its integrated job management tool, any work that you cannot perform immediately joins a queue.
Don’t want to join the queue? The autoscale formula comes into play!
Should we observe a sudden spike in our workload, we might want to avoid pending tasks in the queue. On the other hand, while Batch itself is free of charge, we incur charges for the computer resources (the nodes) we preempt, even if the nodes are idle. Those situations highlight the need to free numerical resources when not needed and to gather them on demand.
The autoscale formula allows for a dynamical pool that can resize depending on a metric declined in different flavors, as shown below.
Time-based adjustment: a predefined number of nodes are allocated during a certain period of time (e.g. during business hours) and reduced (possibly to zero) otherwise. It’s very predictable in terms of budget but you need to know how many concurrent workers are expected. We also note that a sudden spike in the workload cannot be accommodated: tasks may have to join the queue.
Task-based adjustment: here, the number of nodes is adjusted depending on the number of pending tasks. This is a more dynamic option that can accommodate the actual workload, but it comes with latency due to the gathering of numerical resources. Another caveat is that the budget becomes less predictable as nodes can be created on the fly.
Example of a realistic autoscale formula
A more realistic adjustment would combine both scenarios, that is a predefined number of allocated nodes based on the expected average workload with a dynamic component capable of absorbing fluctuations around that average.
An example of a formula implementing that strategy is given by:
$curTime = time();
$workHours = $curTime.hour >= 8 && $curTime.hour < 18;
$isWeekday = $curTime.weekday >= 1 && $curTime.weekday <= 5;
$isWorkingWeekdayHour = $workHours && $isWeekday;
$pd_t_1m = $PendingTasks.GetSample(1)
$pd_t_5m = $PendingTasks.GetSample(TimeInterval_Minute*5)
$pd_t_5m_per = $PendingTasks.GetSamplePercent(TimeInterval_Minute*5);
$tasks = $pd_t_5m_per < 25 ? max(0,$pd_t_1m) : max($pd_t_1m,avg($pd_t_5m));
$targetNodes = $tasks > 0 ? $tasks : max(0, $TargetDedicatedNodes/2);
$TargetDedicatedNodes = $isWorkingWeekdayHour ? max($targetNodes, 50) : 5;
$NodeDeallocationOption = taskcompletion;
This formula ensures that at least 50 nodes are available during business hours with the possibility to spawn new nodes if needed and 5 otherwise. To do so, lines 3 →5 determine whether or not the current time lies within business hours. Lines 7 → 9 get the percentage of pending tasks for the last 5 minutes, as well as the number of pending tasks for the last minute and the last 5 minutes.
If more than 25% of the tasks are pending, we compute the number of desired nodes based on the history load, and otherwise, we set it to the number of pending tasks. That result is finally adapted depending on the current time. The final line ensures that if the pool needs to be resized, no node is deallocated while still running.
Conclusion
Batch computing offers a very convenient and efficient template to perform parallel workload at scale whilst maintaining a reasonable cost, as we saw with Azure Batch. Similar cloud batch computing is also provided by other cloud providers, such as AWS Batch for Amazon or Batch for Google and follow the same principles.
Now it’s your turn to use it in your AI pipeline! Don’t hesitate to take a look at our Terraform module (insert GitHub link when published) that abstracts the configuration of Azure Batch in your CI/CD pipeline to a couple of parameters to provide.
If you found this article useful, don’t hesitate to share it with your friends and colleagues, or feel free to drop the author Renaud a message on Linkedin if you want to talk more on this topic!





